
前面提到,ComfyUI 工作流配置相对复杂。在此,以最基础的“文生图”工作流为例,与大家分享其配置方法。下图展示了文生图工作流全貌。
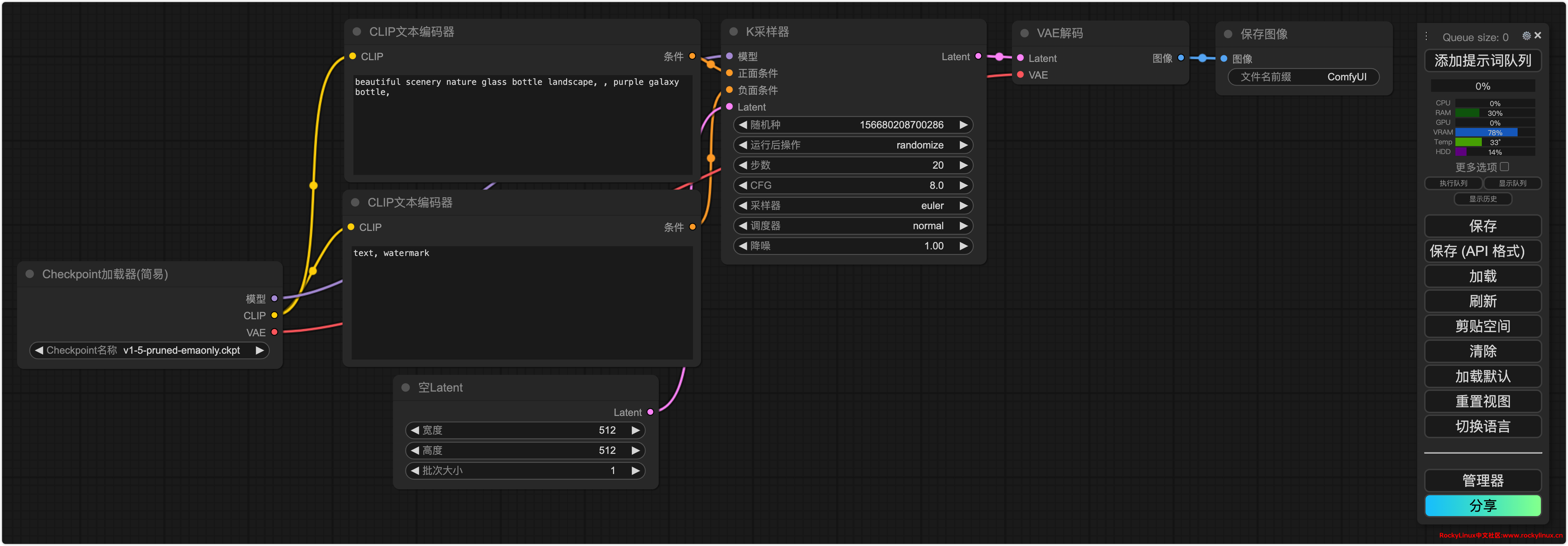
基于上图,木子从左至右来讲解各节点的功能及作用。
CheckPoint 加载器
在这里 CheckPoint 是大模型整个工作流的起始点。在配置时需要选择合适的大模型,并将 VAE 输入连接到 K 采样器。此外,CLIP 节点用于连接正向和负向提示词。VAE 可以直接使用大模型内置的 VAE,或者通过单独的 VAE 解码节点选择自定义的 VAE。
木子这里以 majicMIX realistic 麦橘写实 - v7 | Stable Diffusion Checkpoint | Civitai 模型为例,只需将下载的模型文件放置在 /app/ComfyUI/models/checkpoints 目录中即可完成安装。

CLIP
在 ComfyUI 中,CLIP 节点用于输入提示词,以便生成图像。在使用 CLIP 节点时,需要两个节点:一个用于正向提示词,一个用于负向提示词。
-
正向提示词(Positive Prompt):这是您希望在生成的图像中突显的特征或元素。正向提示词是积极描述性的词语或短语,用于指导模型生成包含这些特定特征的图像。例如,如果您输入“sunset over mountains”作为正向提示词,模型会努力生成一幅包含日落和山景的画面。
-
负向提示词(Negative Prompt):这是您希望在生成的图像中避免的特征或元素。负向提示词是排除性的词语或短语,用于指导模型避免生成包含这些特定特征的图像。例如,如果您不希望图像中出现“rain”或“clouds”,可以将这些词作为负向提示词输入,模型将尽量避免在生成的图像中出现这些元素。
在 ComfyUI 中,正向提示词的 CLIP 节点会链接到 K 采样器(K Sampler),用于指导生成图像的所需特征。类似地,负向提示词的 CLIP 节点也会链接到 K 采样器,用于排除不需要的特征。通过结合正向和负向提示词,您可以更精确地控制生成图像的内容。
例如:木子这里想生成一张风景图。
场景:秋天的枫叶落在崭新的柏油路上,并且图片上不带文字和水印。
正向提醒词:Autumn maple trees with leaves falling on the brand new asphalt road
反向提醒词:text, watermark
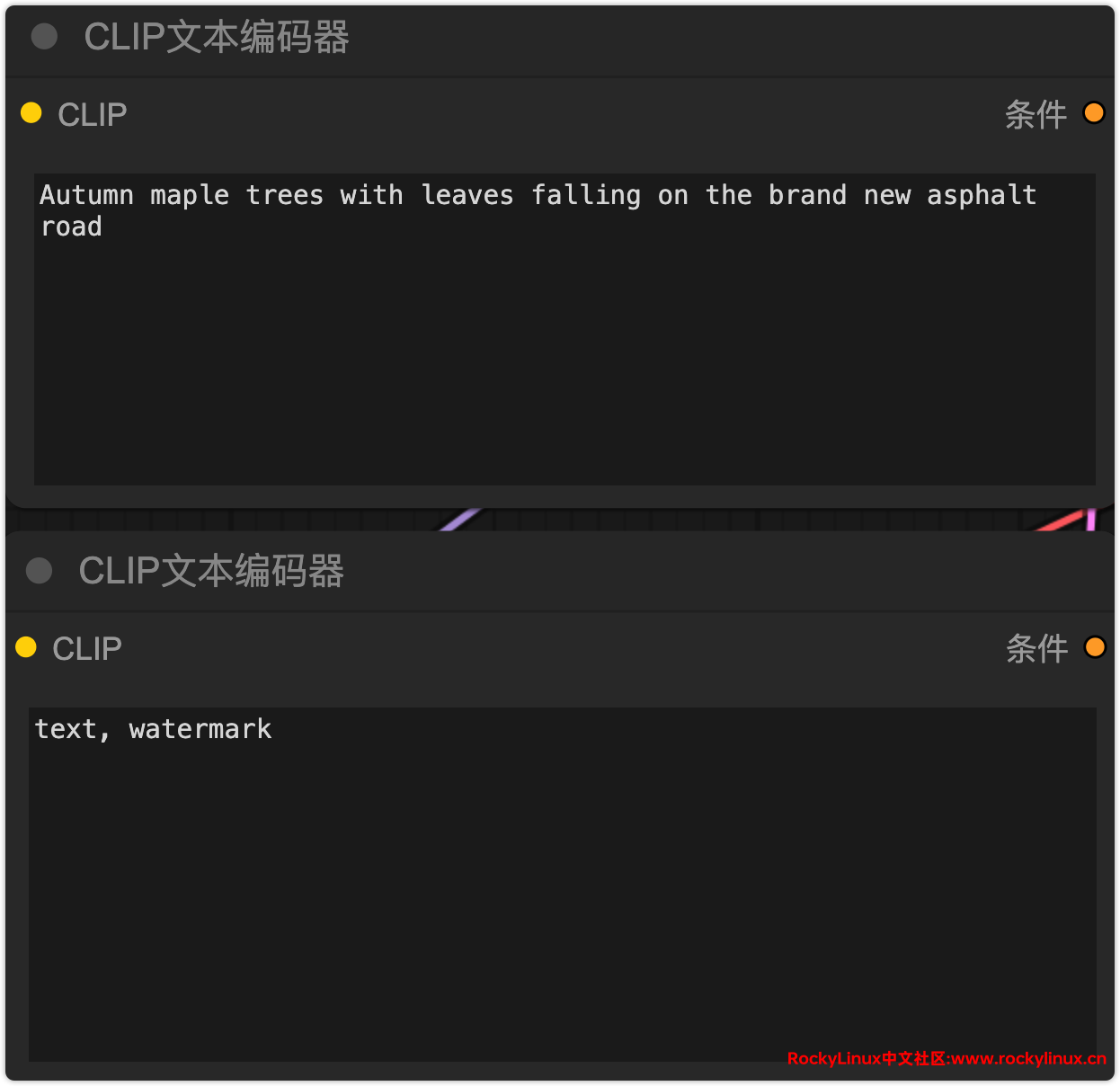
空 Latent
在 ComfyUI 中,“空 latent”(Empty Latent)节点是用于在潜空间(latent space)中创建一个占位图像。这个节点主要用于控制生成图像的尺寸和批次数量。
-
图像尺寸(Image Dimensions):
- 宽度和高度:空 latent 节点可以指定待生成图像的宽度和高度。潜空间中的图像大小将直接影响最终输出的图像尺寸。通过设置这两个参数,可以控制生成的图像是长方形、正方形还是其他比例。常见的尺寸有 512x512、256x256 等,但具体取决于您的需求和模型的能力。
-
批次数量(Batch Size):
- 批处理数量:这是指在一次操作中生成的图像数量。设置批次数量可以有效提高生成图像的效率,特别是在需要大批量图像时。例如,将批次数量设为 4,则在一次生成过程中会同时生成 4 张图像。这样有助于节省时间,并在需要多张图像时更方便地进行观察和比较。
-
潜空间图像(Latent Space Image):
- 潜空间:潜空间是一种高维空间,用于表示图像的抽象特征。在这个空间中,图像被表示为一个低维度的向量(latent vector)。空 latent 节点通过创建一个空白的潜向量来占位,这个向量将作为生成图像的基础。之后,通过模型和提示词的指导,这些潜向量会被解码成实际的图像。
通过配置“空 latent”节点,您可以灵活控制生成图像的尺寸和批量,从而满足不同应用场景的需求。这对于优化工作流的效率和输出质量非常有帮助。
木子这里设置尺寸为 1920 x 1080,并且只生成 1 张。
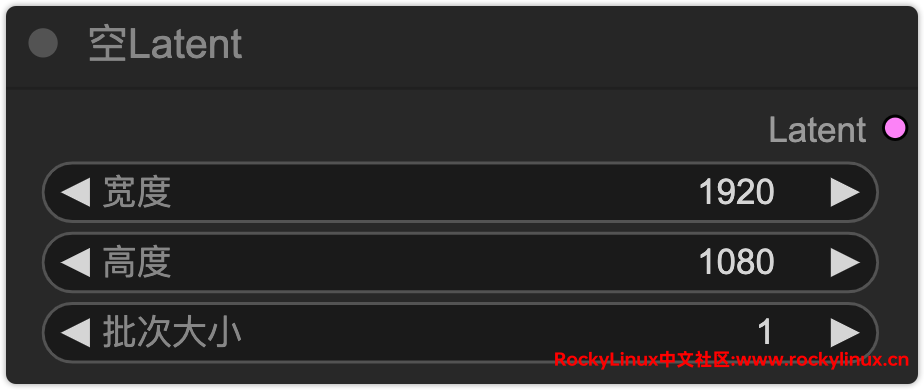
K 采样器
在 Stable Diffusion (SD) 出图流程中,K 采样器和 Latent 是核心组成部分。为了更加清晰地理解它们以及相关参数的含义,下面是详细的解释:
K 采样器 (K Sampler)
K 采样器是图像生成流程中的核心节点,所有输入数据和模型参数都会汇总到这个节点进行最终的计算和采样,生成图像。具体步骤包括:
- 载入模型:使用预先训练好的 Stable Diffusion 模型。
- 提示词输入:结合正向和负向提示词。
- Latent 输入:使用来自潜空间的 Latent 数据。
Latent(潜空间)
Latent 是 Stable Diffusion 内部表示图像信息的一种高维向量表示。在图像生成过程中,它是图像数据在潜空间中的格式表达。它通过 Variational Autoencoder(VAE)来转换:
- VAE 编码:将输入图像编码为潜空间表示。
- VAE 解码:将潜空间表示解码为像素空间图像。
Latent 参数设置
这些参数在生成图像时非常重要,它们影响生成的风格、细节和质量。以下是这些参数的详细说明:
-
Latent 的随机种(Seed):
- 含义:生成图像时用于初始化随机数生成的种子值。相同的种子值会生成相同的图像。
- 作用:通过设置相同的种子值,可以使生成过程可重复,便于调试和对比结果。
-
运行后操作(Post-processing):
- 含义:生成图像后进行的后续处理操作,可能包括色彩调整、细节增强等。
- 作用:提高最终图像的质量或符合特定需求。
-
步数(Steps):
- 含义:生成图像时反向扩散过程的迭代次数。
- 作用:更多的步数通常会产生更细节丰富的图像,但也会增加计算时间。
-
CFG(Classifier-Free Guidance):
- 含义:用于控制提示词对生成图像的影响程度的参数。通常表示为一个比例。
- 作用:较高的值会使模型更严格地跟随提示词,但过高的值可能导致图像质量下降。
-
采样器(Sampler):
- 含义:采样算法,用于决定如何在 Latent 空间中采样数据以生成图像。常见的采样器包括 ddim、euler 等。
- 作用:不同的采样器可能会生成风格和质量不同的图像。
-
调度器(Scheduler):
- 含义:定义反向扩散过程中噪声的调度方式。它决定了噪声的减少路径。
- 作用:调度器的选择会影响图像生成的细节和风格。
-
降噪(Denoising):
- 含义:在图像生成过程中进行噪声抑制的参数。
- 作用:降低生成图像中的随机噪声,从而提高图像质量。不同的降噪水平会影响图像的细致程度和风格。
采样器
在图像生成过程中,不同的采样器决定了如何在潜空间中进行采样。这些采样器的选择会影响生成图像的风格和质量。以下是几种常见的采样器及其含义:
-
DDIM (Denoising Diffusion Implicit Models):
- 含义:DDIM 是一种确定性的采样方法,比传统的扩散模型更高效,能够在更少的步数内生成高质量图像。
- 特点:较快的采样速度和较高的生成质量。
-
Euler:
- 含义:采用欧拉方法进行数值积分,在进化过程中使用逐步的确定性方法生成图像。
- 特点:简单快速,但在生成质量和细节上可能不如其他高级采样器。
-
Heun 和 Heun2:
- 含义:采用 Heun 的方法(即改进欧拉方法)进行数值积分,分为一阶和二阶方法。
- 特点:比欧拉方法更精确,具有较好的平衡性,适合生成质量要求较高的应用。
-
LMS (Laplacian Pyramid Sampling):
- 含义:采用拉普拉斯金字塔方法,通过多层次处理提高图像生成的细节和质量。
- 特点:生成质量较高,尤其适合需要精细细节的场景。
-
DPM_2 (Diffusion Probabilistic Model - 2):
- 含义:基于扩散概率模型的第二代算法,产生的图像质量普遍较高。
- 特点:生成图像的质量和细节较好,但计算复杂度相对较高。
-
DDPM (Denoising Diffusion Probabilistic Models):
- 含义:这是最早提出的降噪扩散概率模型,作为基准模型广泛应用于图像生成。
- 特点:生成过程稳健但速度较慢,所需的步数较多。
总结来说,各种采样器设计上有不同的侧重和优化方向,更快速的采样器可能会牺牲一些细节和质量,而更精细的采样器则可能会增加计算时间。根据实际的需求和资源,可以选择最适合的采样器以达到最佳效果。
在整个生成流程中,用户设置初始参数如随机种子和提示词,模型和参数通过 K 采样器进行采样计算,在潜空间中生成 Latent 数据,最后通过 VAE 解码得到最终像素空间的图像。这些参数的灵活配置使得图像生成过程具有高度可控性和可定制化。
VAE 解码
这个过程就是VAE 解码,将潜空间表示解码为像素空间图像。

保存图像
顾名思义,保存图像即保存当前生成的图像,除了能够在当前页面查看外,还可以在 /app/ComfyUI/output/ 目录下找到所有生成的图片。
文生图的流程非常简单:输入提示词,点击【添加提示词队列】,即可生成您想要的图片。
右击对应图片,选择【保存图像】,可以下载至本地。
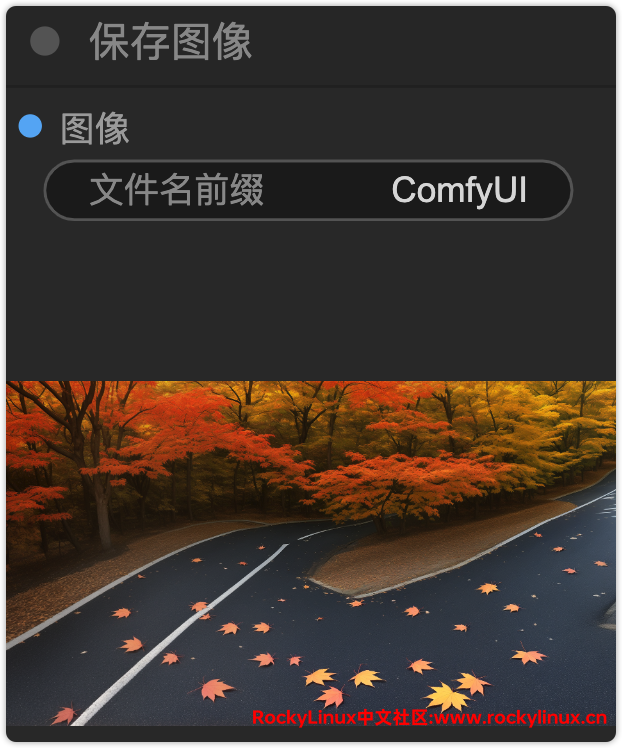
这是木子生成的最终图像。

题外话
本计划将图生图、工作流编辑与管理等写完的,但《Rocky Linux 9 从入门到精通》系列,已经很久没有更新了,确实不应该反客为主,重新回归主线,更新《Rocky Linux 9 从入门到精通》系列。AI 系列佛系更新。










