
概述
本章,您将了解到 Apache httpd 中 MPM 的三种工作模式,即 event、prework 和 worker。
MPM(Multi-Processing Modules,多处理模块):Apache httpd 中的核心组件之一,目的是为了让 Apache httpd 在不同操作系统上发挥最大化的性能和稳定性,该组件主要实现了网络监听、网络请求处理、调度进程或子进程等功能。因为 Apache httpd 本身是跨平台的,不同操作系统对底层网络的请求处理都不太一样,若强行使用一套统一的代码,就没法发挥各自操作系统的原生优势特性,为了在不同平台环境下实现最佳的网络性能以及稳定性,便诞生了 MPM。
在编译安装 Apache httpd 时,由于未指定 --with-mpm=MPM 选项,则 MPM 默认工作模式为 event 。
Shell > /usr/local/apache2/bin/apachectl -V
Server version: Apache/2.4.68 (Unix)
Server built: Jun 13 2026 22:40:36
Server's Module Magic Number: 20120211:142
Server loaded: APR 1.7.6, APR-UTIL 1.6.3, PCRE 10.32 2018-09-10
Compiled using: APR 1.7.6, APR-UTIL 1.6.3, PCRE 10.32 2018-09-10
Architecture: 64-bit
Server MPM: event
threaded: yes (fixed thread count)
forked: yes (variable process count)
Server compiled with....
-D APR_HAS_SENDFILE
-D APR_HAS_MMAP
-D APR_HAVE_IPV6 (IPv4-mapped addresses enabled)
-D APR_USE_PROC_PTHREAD_SERIALIZE
-D APR_USE_PTHREAD_SERIALIZE
-D SINGLE_LISTEN_UNSERIALIZED_ACCEPT
-D APR_HAS_OTHER_CHILD
-D AP_HAVE_RELIABLE_PIPED_LOGS
-D DYNAMIC_MODULE_LIMIT=256
-D HTTPD_ROOT="/usr/local/apache2/"
-D SUEXEC_BIN="/usr/local/apache2//bin/suexec"
-D DEFAULT_PIDLOG="logs/httpd.pid"
-D DEFAULT_SCOREBOARD="logs/apache_runtime_status"
-D DEFAULT_ERRORLOG="logs/error_log"
-D AP_TYPES_CONFIG_FILE="conf/mime.types"
-D SERVER_CONFIG_FILE="conf/httpd.conf"进程与线程
进程(Process):是一个具有一定独立功能的程序关于某个数据集合的一次运行活动,是系统进行「资源分配和调度」的一个独立单位。从这段话中可知:
- 进程是程序的「一次执行」,即进程是程序的一个实例(或实体)
- 进程是程序运行在一个「数据集合」上的过程
- 进程反映了程序以及数据在处理机上顺序执行后的活动状态
- 进程是操作系统进行资源分配和调度的一个独立单位(基本单位)
线程(Thread):进程的轻量型实体,是一系列按照顺序执行的指令集合,是一条执行路径,不能单独存在,必须包含在进程中(换言之,一个进程可以包含单个或多个线程)。线程是操作系统中运算调度的最小单位。
每个进程都有自己的内存上下文(资源和地址空间),而来自 同一进程 的 线程 则共享相同的上下文。
在 GNU/Linux 操作系统中,每个进程都有:
- PID - Process IDentifier,唯一的进程标识符。
- PPID - Parent Process IDentifier,父进程的唯一标识符
通过连续的隶属关系,init 进程(也就是 systemd,其 pid 为 1 )是所有进程之父。
进程的说明:
- 进程之间存在父与子的关系
- 子进程是父进程调用 fork() 原语(primitive,计算机术语)并复制自己的代码来创建子进程的结果
- 一个进程始终由父进程进行创建
- 一个父进程可以有多个子进程
- 子进程的 PID 会返回给父进程,以便父进程与之对话
- 每个子进程都有父进程的标识符 PPID
- PID 中的数字代表执行时的进程,当进程结束时,该数字可再次用于另一个进程
- 多次运行同一命令将每次产生不同的 PID 数字
孤儿进程(orphan process) - 当父进程死亡时,其子进程被称为 孤儿。init 进程(systemd,PID 为 1 )会收养这些特殊状态的进程,并完成状态收集,直到它们被销毁。从概念上讲,孤儿院进程不会造成任何伤害。
僵尸进程(zombie process) - 子进程完成工作并被终止之后,其父进程需要调用信号处理函数 wait() 或 waitpid() 来获取子进程的终止状态。如果父进程没有这样做,虽然子进程已经退出,但它仍然在系统进程表中保留一些退出状态信息,因为父进程无法获取子进程的状态信息,这些进程将持续占用进程表中的资源,我们将这种状态下的进程称为 僵尸。
僵尸进程的危害:
- 占用系统资源并导致机器性能下降
- 无法生成新的子进程。
prework
prework:稳定优先的多进程模式。这是一种古老但非常可靠的模式,其核心思想是「预先创建子进程」,工作原理如下:
Apache httpd 在启动时,父进程会预先创建(fork)一批子进程,并始终保持一定数量的空闲进程随时待命,之所以要预先创建,是为了减少频繁创建以及销毁进程的开销。每个子进程只有一个线程,互相独立、互不影响,以提高稳定性。在一个时间点内,一个线程只能处理一个请求,并且会根据并发请求数量动态生成更多的子进程,具体生成多少由配置文件决定。
- 优点 - 稳定且安全
- 缺点 - 占用更加多的系统资源且并不适合高并发场景
worker
worker:多进程 + 多线程的混合模式。工作原理如下:
Apache httpd 在启动时,父进程会根据配置文件的配置指令预先创建(fork)一定数量的子进程。每个子进程会生成固定数量的线程(包括多个服务线程以及一个监听进程),每个线程处理一个请求。如果某个子进程崩溃,只会影响该子进程内的线程,而其他子进程仍可正常工作,从而保证了服务器的整体稳定性。
- 优点 - 占用内存低(相比每个请求独占一个进程的 prefork ,worker 在处理大量并发请求时能显著减少内存消耗);并发性能强(线程的创建和切换开销小于进程)
- 缺点 - 线程安全问题导致的未知错误(由于在同一个进程当中的线程共享相同的内存资源,若使用了非线程安全的模块,可能会导致出现未知错误);Keep-Alive 长连接阻塞问题(当一个线程处理一个 Keep-Alive 连接时,即使中间没有请求,该线程也会一直被占用,直到超时。在高并发场景中,会出现大量线程被空闲连接占据的情况,此时的 Apache httpd 无法服务新的请求,造成资源浪费)
HTTP Keep-Alive 和 TCP Keepalive
众所周知,现如今的互联网根据普遍采用的是 TCP/IP 四层模型,而面向教学时则会称 TCP/IP 五层模型。TCP/IP 模型不像 ISO/OSI 模型那样是先有理论框架再填充协议,而是先有协议,后有模型,因此人们也会将 TCP/IP 模型称为 TCP/IP 协议族。

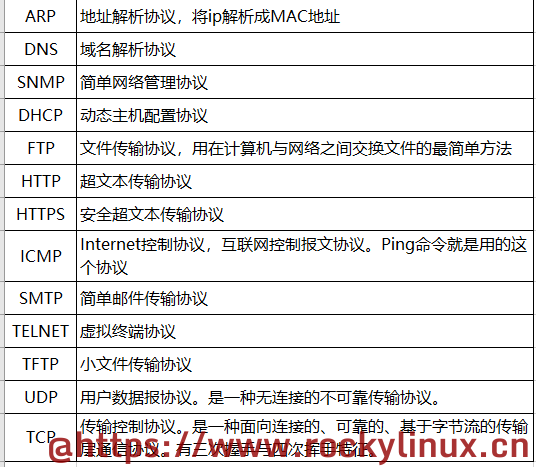
- 应用层的协议:ftp、https、http、dns、smtp、snmp等这些,属于应用层的协议。
- 传输层的协议:TCP 与 UDP,选择其中之一或者两个都选。
- 网络层的协议:IP 协议、ICMP 协议、IGMP 协议、ARP 协议
- 网络接口层协议:ppp 协议,pppoe 拨号协议

在本文中,Keep-Alive 特指 HTTP Keep-Alive,而不是 TCP Keepalive,两者对比如下:
| 特性 | HTTP Keep-Alive | TCP Keepalive |
|---|---|---|
| 工作层级 | 应用层 | 传输层 |
| 实现 | 由应用程序(如浏览器、Web服务器)实现 | 由操作系统内核实现 |
| 目的 | 复用 TCP 连接,提升效率与性能 | 检测无效连接,释放服务器资源 |
| 触发时机 | 在一次 HTTP 请求/响应完成后,决定是否保持连接以备下次复用 | 在一个 TCP 连接长时间空闲(无数据传输)后触发 |
| 工作方式 | 等待一段时间,看是否有新请求 | 发送探测包,看对方是否响应 |
TCP Keepalive 的诞生背景:在早期的网络通信中,当客户端和服务器建立连接后,若客户端突然出现死机、崩溃、断电或者网络中断的情况,服务器端往往毫不知情,它会一直傻傻地维护着这个实际上已经失效的连接,而这些失效连接还占用着内存、文件描述符等系统资源。久而久之,大量这样的 "僵尸连接" 会拖垮服务器的性能。于是,人们在 TCP 协议中引入了 Keepalive 机制,这种机制相当于为 TCP 连接开启 "心跳包" 监听:
- 目的 - 让服务器端能快速感知到对方是否还 "活着",从而及时清理无效连接释放资源
- 工作方式 - 如果连接在一段时间内(通常为 2 小时)没有任何数据传输,服务器就会发送一个探测包。若对方有正常响应,说明连接还处于活跃状态;若多次探测都没有回应,就判定为失效的连接,服务器会主动关闭这个连接并释放资源
HTTP Keep-Alive 的诞生背景:在早期的 HTTP/1.0 时代,默认是 "短连接"。这意味着浏览器每请求一个资源(比如一个 HTML 页面、一张图片、一个 CSS 文件),都要经历一次完整的 TCP 连接建立和关闭过程:
- 三次握手(建立连接)
- 传输数据
- 四次挥手(关闭连接)
如果一个网页有 50 张图片,这个过程就要重复 50 次,开销巨大的同时效率还非常低。大约从 1996 年开始,一些浏览器和服务器厂商受不了了,开始在 HTTP/1.0 中实验性地扩展支持 Keep-Alive 长连接,目的很简单 —— 一次连接,多次使用。浏览器和服务器之间只需建立一次 TCP 连接,就可以在这条连接上串行地传输多个 HTTP 请求和响应,直到所有资源都传输完毕或超时后才关闭。后来该特性成为 HTTP/1.1 的默认特性,即现在我们所说的 "持久连接(Persistent Connections)"。
event
event:work 工作模式的变体增强版,主要解决 work 工作模式下 keep-alive 长连接阻塞问题。在配置上,event 兼容 worker 的配置指令。










