
概述
本章,您将学习到 MySQL 8 中有关锁机制的知识,内容包括:
- 锁机制的分类
- 演示 InnoDB 存储引擎的行锁
- 演示 InnoDB 存储引擎的表锁
- 锁的查看
- 有关乐观锁、全局锁和死锁的内容
- MVCC
由于内容较多,本文档说明最后一部分内容 —— MVCC
基本概念
| 隔离级别(从低到高) | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 1(READ UNCOMMITTED,读取未提交的数据) | 会出现 | 会出现 | 会出现 |
| 2(READ COMMITTED,读取提交的数据) | 不会出现 | 会出现 | 会出现 |
| 3(REPEATABLE-READ,可重复读,全局默认隔离级别) | 不会出现 | 不会出现 | 会出现 |
| 4(SERIALIZABLE,序列化) | 不会出现 | 不会出现 | 不会出现 |
MVCC(Multi-Version Concurrency Control,多版本并发控制):一种提高并发性的强大技术,其通过数据行的的多个版本管理(多个版本需要依赖 Undo Log )来实现数据库的并发控制。对于 InnoDB 而言,其主要作用是 —— 提高高并发环境下的读写性能,减少锁竞争,确保数据一致性。
在 InnoDB 存储引擎中,为了支撑起 MVCC 的高效运转,有两大核心读取机制:
- 快照读(consistent read)- 事务读取的是数据的历史快照版本,而非当前最新值,属于非阻塞读
- 当前读(current read) - 事务读取的是数据的最新提交版本,并加锁以保证一致性
两者的对比如下表所示:
| 对比项 | 快照读 | 当前读 |
|---|---|---|
| 触发 | 普通 SELECT 语句(未加锁)在 READ COMMITTED 和 REPEATABLE READ 隔离级别下自动触发 | 排他锁(select ... for update;)和共享锁(select ... lock in share mode;)显式触发;DML 操作(insert、update、delete)隐式触发 |
| 隔离级别 | READ COMMITTED、REPEATABLE READ 隔离级别下默认使用 | 全部 |
| 版本控制 | 通过 MVCC(多版本并发控制)读取历史版本数据 | 读取最新提交版本数据,不依赖历史版本 |
| 锁机制 | 不加锁,避免锁竞争 | 加排他锁(X 锁)或共享锁(S 锁),防止数据修改 |
| 数据一致性 | 避免脏读、不可重复读(REPEATABLE READ 隔离级别下) | 避免脏读、不可重复读、幻读(REPEATABLE READ 隔离级别下) |
| 性能 | 高并发读性能优异,减少锁开销 | 读写冲突时加锁可能导致性能下降 |
| 适用场景 | 读操作频繁、对数据一致性要求较低的场景 | 需要数据一致性保证的场景(如事务内修改数据) |
| 示例 SQL | SELECT * FROM table WHERE id = 1; | SELECT * FROM table WHERE id = 1 FOR UPDATE; |
并发场景
在 InnoDB 存储引擎中,当使用者需要对相同的行数据进行操作时,可以出现以下三种情况:
- 读-读(Read-Read)
- 读-写 或 写-读(Read-Write / Write-Read)
- 写-写(Write-Write)
三种情况的对比如下表所示:
| 对比项 | Read-Read | Read-Write / Write-Read | Write-Write |
|---|---|---|---|
| 定义 | 多个事务同时读取同一行数据 | 一个事务读取,另一个事务修改同一行数据 | 多个事务同时修改同一行数据 |
| 是否发生冲突 | 无冲突 | 可能引发脏读、不可重复读、幻读(取决于隔离级别) | 严格冲突,不允许并发 |
| 核心机制 | MVCC + 快照读 | 快照读(普通 SELECT)与当前读(显式加锁)协同;隔离级别决定默认行为 | 排他锁(X 锁)串行化执行 |
| 是否加锁 | 不加锁 | 快照读不加锁;当前读加共享锁(S 锁)或排他锁(X 锁) | 加排他锁(X 锁) |
| 隔离级别影响 | 所有隔离级别均无影响 | READ UNCOMMITTED 下允许脏读;READ COMMITTED 下避免脏读,允许不可重复读;REPEATABLE READ 下避免前两者,需间隙锁防幻读 | 所有隔离级别下均禁止并发写入,机制一致 |
| 性能影响 | 极高并发且无阻塞,性能最优 | 快照读下是高性能;当前读下可能阻塞,导致性能下降 | 串行化,吞吐量低,易形成瓶颈 |
| 示例 SQL | SELECT * FROM users WHERE id = 100; | 快照读:SELECT * FROM users WHERE id = 100; 当前读:SELECT * FROM users WHERE id = 100 FOR UPDATE; |
UPDATE users SET name = 'Alice' WHERE id = 100; |
| 解决的核心问题 | 实现高并发读取,消除读-读竞争 | 解决读写并发下的数据一致性问题(脏读、不可重复读、幻读) | 保证数据最终一致性,防止脏写 |
| 是否依赖 MVCC | 完全依赖 | 快照读依赖 MVCC;当前读绕过 MVCC,直接读最新版本 | 不依赖 MVCC,仅依赖锁机制 |
了解 MVCC
主要包括三部分的内容:
- 隐藏字段
- Undo Log
- ReadView
隐藏字段
当使用者在当前库中新创建一张表后,无论是使用 show createa table 表名; 还是 desc 表名; ,都不能看见隐藏字段,这是因为 InnoDB 的底层机制已经帮你自动配置了。
在 InnoDB 中,所谓 MVCC 的隐藏字段,指的是 DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID,如下表的说明:
| DB_TRX_ID | DB_ROLL_PTR | DB_ROW_ID | |
|---|---|---|---|
| 是否必须存在 | 是 | 是 | 否 |
| 大小 | 6 字节 | 7 字节 | 6 字节 |
| 作用 | 记录最后一次修改该行的事务 ID | 指向 Undo Log 的回滚指针 | 隐藏的行唯一标识符 |
| 说明 | 每次更新行数据时,InnoDB 会将当前事务的 ID 写入此字段,用于判断版本可见性 | 通过该指针可追溯该行的历史版本,是实现快照读和事务回滚的核心机制 | 当 Innodb 自动产生聚集索引时,聚集索引会包括这个行标识符的值。 |
Undo Log
MVCC(多版本并发控制)中的多个数据版本管理是依靠什么来实现的?
Undo Log 的版本链。
首先我们回顾下前面关于表空间的知识
表空间:
表空间是逻辑层与物理层的中间桥梁,它是用户逻辑对象(表、索引等)的存储空间,用来统一管理空间中的数据文件。
表空间的属性包括:
- 表空间在物理层上对应着若干个容器 ,容器可以是目录名称、文件名或者设备名称
- 一个库可以包含多个表空间,但一个表空间只能属于一个库
- 一个表空间可以包含多个数据文件,但一个数据文件只能属于一个表空间
表空间是逻辑存储,其按照表空间(Tablespaces) ---> 段(Segment) ---> 区(Extent) ---> 页(Page) ---> 行(Row)的层级结构构成。
撤销表空间(回滚表空间,Undo Tablespaces)专门用于存储撤销日志(Undo log),MySQL 8.x 及以上版本进行初始化时,默认会在数据目录中创建两个撤销表空间文件(无 .ibu 后缀标识),这些文件以回滚段的结构形式存储回滚日志。
Shell > ls -lh /usr/local/mysql8/data/undo_00*
-rw-r----- 1 mysql mysql 16M Nov 18 19:07 /usr/local/mysql8/data/undo_001
-rw-r----- 1 mysql mysql 16M Nov 18 19:07 /usr/local/mysql8/data/undo_002除了初始化时默认创建的两个撤销表空间之外,用户可使用 create undo tablespace 语法来创建专属的撤销表空间,该语法关联到文件时必须有 .ibu 后缀标识,语法如下:
CREATE UNDO TABLESPACE tablespace_name ADD DATAFILE 'file_name.ibu';Q:Undo Log 什么时候生成记录呢?
数据修改时:每当事务修改数据(如 update 或 delete 操作)时,InnoDB 会为该操作生成一个 Undo Log 记录,存储修改前的数据值(即数据的前映像)。例如,事务 A 更新 balance 字段时,Undo Log 记录旧的 balance 值。
insert 操作也会生成 Undo Log 记录,但仅用于事务的回滚,并不参与到 MVCC 多版本管理。
| 操作类型 | 是否生成 Undo Log | 是否用于 MVCC 多版本链 | 提交后是否保留 |
|---|---|---|---|
| insert | 是(仅用于回滚) | 否 | 否(可立即清理) |
| update | 是 | 是 | 是(需维持版本链) |
| delete | 是 | 是 | 是(需维持版本链) |
假设您当前库下有个 mvcc 的表,包含 id(主键约束,自增列,int 类型) 和 name(varchar(10) 类型) 两个字段。
连接会话的事务1 执行 insert into mvcc values(10,'king'); 并提交。因为已经有主键约束,所以不存在 DB_ROW_ID 隐藏字段。
| id | name | DB_TRX_ID | DB_ROLL_PTR |
|---|---|---|---|
| 10 | king | 1024(事务 ID 默认自增,此处假设为 1024) | null |
连接会话的事务2 执行 update mvcc set name='wang' where id=10; 更新操作并提交,此时除了修改 name 这个字段下面的数据记录外,事务 ID 以及回滚指针字段下的数据记录都会变化。回滚指针指向上一个版本。
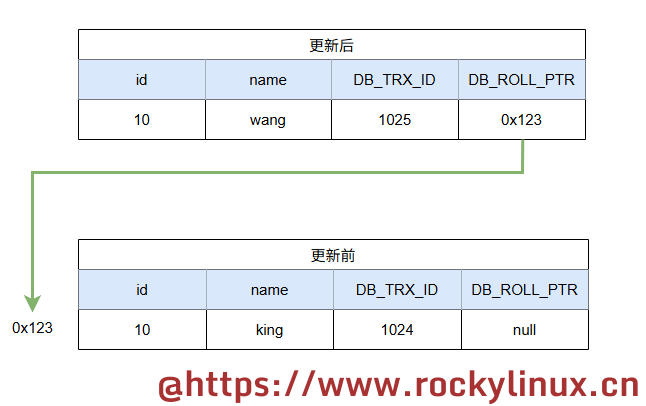
连接会话的事务3 执行 update mvcc set id=20 where id=10; 更新操作并提交,此时出现了多个历史版本记录,如下所示。多次修改后,就构成了我们说的 Undo Log 版本链。从链表角度来看,这是一个单向链表,其中链头节点是最新版本,链尾节点是最早的历史版本。
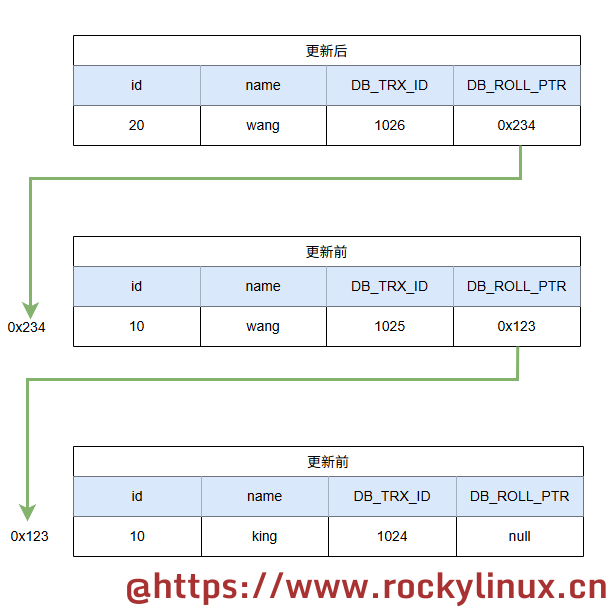
Q:Undo Log 中,对于同一行数据的修改而言,版本链的长度(修改所产生的历史版本数量)有无限制?
无显式限制,但有实际运行时的资源约束。当版本链的长度过长时,查询需遍历更多历史版本,导致读取性能显著下降,甚至引发 "版本链爆炸" 问题,影响整个数据库的稳定性。当版本链过长时,MySQL 通过专门的 Purge 线程来自动清理那些不再需要的 Undo Log 版本,释放出存储空间并带来数据库的稳定性。
Purge 线程会检查每个 Undo Log 版本是否仍被当前活跃事务的读视图(ReadView)所引用。只有当所有可能访问该版本的事务均已提交或回滚,该版本才会被标记为可清理。
ReadView(读视图)
在 MVCC 机制中,多个事务对同一行记录进行更新时会产生多个历史版本,这些修改的历史版本保存在 Undo Log 中,若需要读取该行数据的某个历史版本,就需要 ReadView。换言之,ReadView 是用来管理数据历史版本的规则或机制,判断版本链中的哪些版本是当前事务可见的。
因为 READ UNCOMMITTED 隔离级别可以读到未提交的事务的数据(即允许脏读),所以其读取的是最新版本的数据,换言之,RU 隔离级别不依赖 MVCC ,也不需要 ReadView。至于 SERIALIZABLE 隔离级别,它采用加锁机制(如间隙锁、临键锁)来完全阻止并发写入,从而保证事务串行执行,它不依赖 MVCC,也不需要 ReadView。
因此,ReadView 或 MVCC 只针对 RC 和 RR 这两个隔离级别。
Q:什么情况下会生成 ReadView 这种规则呢?
- RC 隔离级别下:每次执行
SELECT语句时,InnoDB 都会动态创建一个新的 ReadView。这意味着每次查询都能看到其他事务已提交的最新数据,因此可能在同一个事务中读取到不同版本的数据(也就是 "不可重复读")。 - RR 隔离级别下:事务开始后(
start transaction;)首次执行普通SELECT语句,InnoDB 会为该事务创建一个固定不变的 ReadView。此后,事务内所有后续查询都复用这个初始 ReadView,确保在整个事务生命周期内读取到一致的历史版本数据,从而避免 "不可重复读",结合间隙锁(Gap Locks)和临键锁(Next-key Locks),可进一步防止 "幻读" 出现 。
单个 ReadView 包含以下四个核心字段:
| 字段名称 | 含义 | 说明 |
|---|---|---|
| m_ids | 活跃事务 ID 列表 | 生成 ReadView 时,所有未提交事务的 ID 组成的集合 |
| m_low_limit_id | 最小活跃事务 ID | 最早开始但尚未提交的事务 ID |
| m_up_limit_id | 下一个预分配事务 ID | 当前系统中已分配的最大事务 ID + 1,代表未来将要分配的事务 ID |
| m_creator_trx_id | 创建者事务 ID | 生成该 ReadView 的当前事务的 ID |
活跃事务:已开启但尚未提交或回滚的事务,其事务 ID 在系统中仍处于 "活跃" 状态,因此称为活跃事务。
ReadView 还涉及到可见性判断算法(有些资料也称可见性算法):
- 若记录 DB_TRX_ID = m_creator_trx_id ,表示当前事务正在访问自身的修改记录,所以该版本对当前事务可见
- 若记录 DB_TRX_ID < m_low_limit_id ,表示修改记录的事务早于 ReadView 生成前提交,所以该版本对当前事务可见
- 若记录 DB_TRX_ID >= m_up_limit_id ,表示修改记录的事务在 ReadView 生成后才启动,所以该版本对当前事务不可见
-
若记录 m_low_limit_id <= DB_TRX_ID < m_up_limit_id,则需要看情况
- 如果 DB_TRX_ID 在 m_ids 的事务 ID 集合中,则表示生成 ReadView 时,修改这条数据的事务还处于 "活跃未提交" 状态,所以该版本对当前事务不可见
- 如果 DB_TRX_ID 不在 m_ids 的事务 ID 集合中,则表示生成 ReadView 时,修改这条数据的事务已经提交,所以该版本对当前事务可见
在 RR 隔离级别下,假设你开启了一个事务(ID=10),执行普通 select 语句时生成了 ReadView:
- m_ids={101,103,105}(这三个事务还没提交)
- m_low_limit_id=100(当前最小的活跃事务 ID 是 100)
- m_up_limit_id=200(下一个要分配的事务 ID 是 200)
此时你查询一条数据,不同数据版本的可见性如下:
- 数据版本的 DB_TRX_ID=10 - 是你自己改的,所以该版本对当前事务可见
- 数据版本的 DB_TRX_ID=99 - 事务 99 在你生成 ReadView 前就提交了,所以该版本对当前事务可见
- 数据版本的 DB_TRX_ID=200 - 事务 200 是你生成 ReadView 后才启动的,所以该版本对当前事务不可见
- 数据版本的 DB_TRX_ID=101 - 事务 101 在活跃集合里(没提交),所以该版本对当前事务不可见
- 数据版本的 DB_TRX_ID=102 - 事务 102 不在活跃集合里(已提交),所以该版本对当前事务可见
ReadView 和 MVCC 的实际案例
使用的是默认 RR 隔离级别。
use locks;
select * from tlock1;
+----+------+
| id | name |
+----+------+
| 1 | kone |
| 7 | john |
| 15 | lee |
+----+------+
3 rows in set (0.03 sec)
desc tlock1;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(10) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)| 时间步骤 | Session 1 | Sessios 2 | Session 3 |
|---|---|---|---|
| 步骤1 | use locks; set autocommit=0; start transaction; update tlock1 set name='Jack' where id=15; |
||
| 步骤2 | use locks; set autocommit=0; start transaction; |
||
| 步骤3 | use locks; select * from information_schema.innodb_trx; |
||
| 步骤4 | commit; | ||
| 步骤5 | select * from tlock1; | ||
| 步骤6 | select * from information_schema.innodb_trx; | ||
| 步骤 7 | rollback; |
-
Session 1 中,
update tlock1 set name='Jack' where id=15;表示持有 MDL 读锁 -
Session 3 的步骤3中,通过
select * from information_schema.innodb_trx;的输出可知, Session 1 的事务 ID 为 31270select * from information_schema.innodb_trx\G; *************************** 1. row *************************** trx_id: 31270 trx_state: RUNNING trx_started: 2025-12-21 18:04:33 ... -
Session 3 的步骤6中,通过
select * from information_schema.innodb_trx;\G的输出可知, Session 2 的事务 ID 为 421805598646272select * from information_schema.innodb_trx\G; *************************** 1. row *************************** trx_id: 421805598646272 trx_state: RUNNING trx_started: 2025-12-21 18:07:54 ... -
Session 2 中,
select * from tlock1;表示生成 ReadView,又由于 Session 1 的事务已经提交,相当于记录的DB_TRX_ID < m_low_limit_id,因此其他事务的提交修改在当前事务中是可见的select * from tlock1; +----+------+ | id | name | +----+------+ | 1 | kone | | 7 | john | | 15 | Jack | +----+------+ 3 rows in set (0.00 sec) -
请注意! Session 2 中的
select * from tlock1;并不是 "不可重复读"
不可重复读 - 指在一个事务内,最开始读到的数据和事务结束之前读到的数据不一致,其产生原因如下:
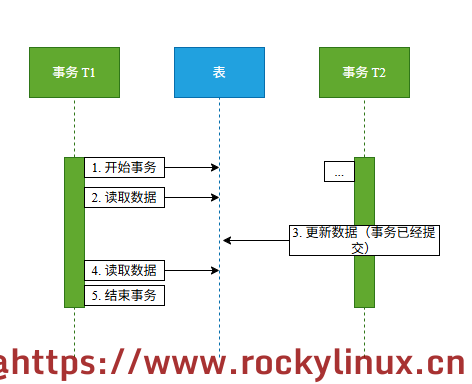
Q:为什么 RR 隔离级别可以不出现 "不可重复读" 现象呢?
结合 ReadView 可知,因为第一次 select 读取后就将 ReadView 固定了。
| 时间步骤 | Session 3 | Session 4 |
|---|---|---|
| 步骤1 | use locks; set autocommit=0; start transaction; select * from tlock1; |
|
| 步骤2 | use locks; set autocommit=0; start transaction; update tlock1 set name='J' where id=7; commit; |
|
| 步骤3 | select * from tlock1; | |
| 步骤4 | rollback; |
-
Session 3 的步骤1 中,
select * from tlock1;的输出如下:select * from tlock1; +----+------+ | id | name | +----+------+ | 1 | kone | | 7 | john | | 15 | Jack | +----+------+ 3 rows in set (0.00 sec) -
Session 3 的步骤3 中,
select * from tlock1;的输出如下:select * from tlock1; +----+------+ | id | name | +----+------+ | 1 | kone | | 7 | john | ←← 无变化 | 15 | Jack | +----+------+ 3 rows in set (0.00 sec)
RR 隔离级别要想解决 "不可重复读" 现象,有一个重要的条件 —— 必须在其他事务提交之前读,将 ReadView 固定。










