
概述
本章开始,您将进入到 MySQL Cluster 的学习。
众所周知,MySQL 根据许可类型的不同,可划分为:
- MySQL Community Server - 开源免费版本,遵循 GPL 协议。
- MySQL Enterprise Edition - 商业付费版本,提供企业级扩展功能。
- MySQL Cluster - 分布式数据库解决方案(商业或社区版)。
集群和分布式概述
Q:什么是集群?
简单来说,就是指将一组(或者若干个)相互独立的计算机通过高速网络组成的一个较大的计算机服务系统,每个集群节点(集群中的每台计算机)都拥有各自独立的 操作系统 实例。集群中的计算机之间可以互相通信,这些计算机通过软件控制或调度协同工作,为用户提供应用程序、服务、数据、系统资源等。当请求用户请求集群系统的资源时,就感觉是一台单一的独立服务器,但其实背后是无数单一计算机组成的集群环境。
集群优点:
- 高性能。对于一些要计算的密集型应用,例如天气预报、天文台、实验模拟等,单台服务器无法胜任这种级别的计算任务,通过集群技术可将多台服务器的计算能力整合起来,并行计算获得超高的计算能力。
- 高伸缩与扩展性。单台服务器只能通过更改自身的硬件才能获得伸缩性,但是在集群环境中,您可以自由调度各个节点,当集群环境中需要增加节点获得资源的扩展性时,只需将新的单台服务器加入到集群环境中即可。
- 高可用性。集群系统可以把正常运行的时间提高到大于99.9%。单一节点的故障不影响整个集群系统的运行。
- 易管理性。集群系统在物理层面会非常大,但在管理上会比较简单,就如同管理单一系统一样。
- 科学计算集群(HPC)
- 负载均衡集群(LB)
- 高可用集群(HA)
通常所说的集群强调的是计算机的物理形态与统一管理,但有时也强调软件的集群,即将同一个软件(或组件或系统)部署在集群环境的各个计算机上,这也被称为 集群。分布式指的是将一个业务系统拆分成多个子系统或组件或子业务(业务系统的拆分就类比开发者代码层面的解耦性),它是一种工作方式,这些组件共同协作组成一个复杂的业务系统。一个好的设计方案是将集群与分布式结合使用,先分布式后集群,具体的实现就是先将业务拆入成多个子系统(或组件或子业务),然后针对每个子系统(或组件或子业务)进行集群化部署。
MySQL 集群环境的一般信息与要求
MySQL Cluster 需要了解的一些重要信息:
- MySQL Cluster 使用 NDB 存储引擎(也称 NDBCLUSTER 存储引擎)而非常规的 Innodb 存储引擎,该存储引擎专为集群环境、分布式架构而设计
-
从 8.0.13 版本开始,MySQL NDB Cluster 采用与 MySQL Server 8.0 系列版本相同的发布策略,版本对齐之后:
- 功能同步,共享最新特性
- 生命周期统一
- 部署与工具链的一体化
- 解决了历史遗留的兼容性问题
- 有关 MySQL NDB Cluster 的文档信息,参阅这里 —— https://dev.mysql.com/doc/refman/8.4/en/mysql-cluster.html
-
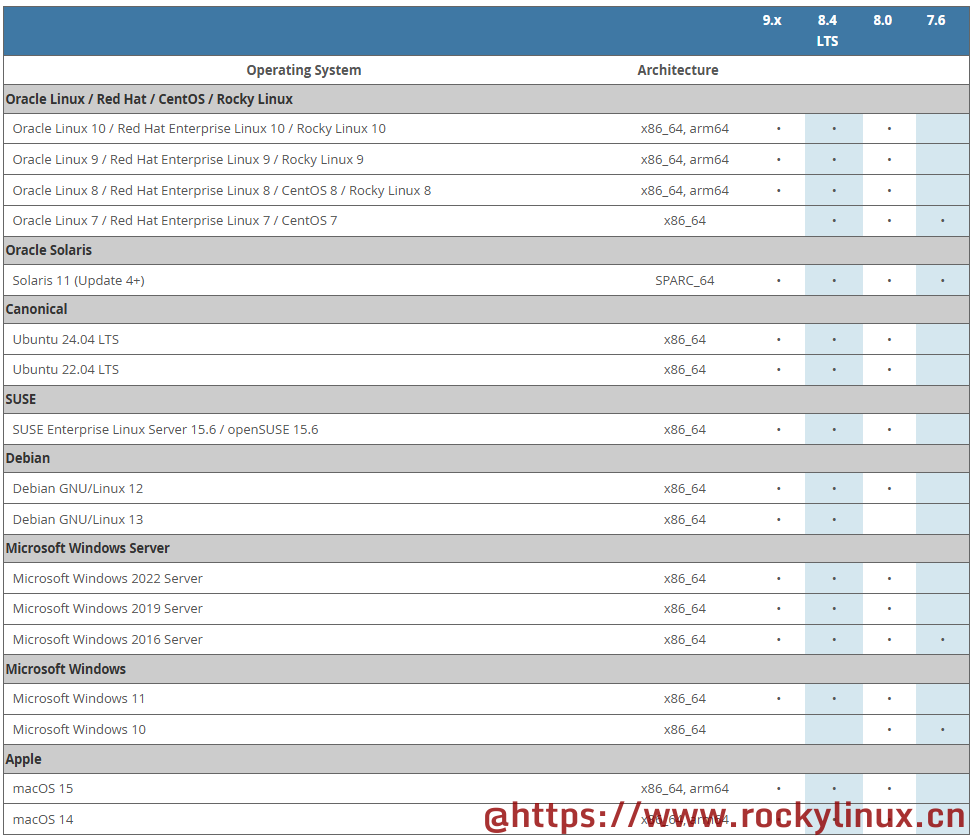
MySQL NDB Cluster 支持多个平台,参阅下图:

- MySQL NDB Cluster 8.0 或 8.4 都可以适用于生产环境。而 7.4 以及之前更早版本已经不在维护,不建议在生产环境下使用
InnoDB 存储引擎与 NDB 存储引擎的对比
以下内容来自于官方文档:
| 特性 | InnoDB(MySQL 8.4) | NDB 8.4 |
|---|---|---|
| MySQL 服务器版本 | 8.4 | 8.4 |
| 存储限制 | 64TB | 128TB |
| 外键约束 | 支持 | 支持 |
| 事务 | 所有标准类型 | READ COMMITED 隔离级别 |
| MVCC | 支持 | 不支持 |
| 数据压缩 | 支持 | 不支持 |
| 大行支持机制(大于 14K) | 对 VARBINARY、VARCHAR、BLOB和 TEXT 列的支持 | 仅支持 BLOB 和 TEXT 列(使用这些类型存储大量数据可能会降低 NDB 性能) |
| 复制技术 | 支持异步复制和半同步复制 | 在 NDB 集群内部的自动同步复制;NDB 集群与 NDB 集群之间使用异步复制(不支持半同步复制) |
| 读取操作的横向扩展 | 支持 | 支持 |
| 写入操作的横向扩展 | 需要应用级的分片 | 支持 |
| HA | 内置,来自 InnoDB Cluster | 支持 (被设计为 99.999% 的正常运行时间) |
| 节点故障恢复与切换 | 来自 MySQL 组复制 | 自动 |
| 节点故障恢复时间 | 30秒或更久 | 通常小于 1 秒 |
| 实时性能监控 | 不支持 | 支持 |
| In-Memory 表 | 不支持 | 支持 |
| 多源复制冲突检测与解决 | 支持 | 支持 |
| 哈希索引 | 不支持 | 支持 |
| 在线添加节点 | 使用 MySQL Group Replication 对副本读取或写入 | 支持(所有节点类型) |
| 在线升级 | 支持 | 支持 |
| 在线模式修改 | 支持 | 支持 |
网络要求
MySQL NDB Cluster 不适用于吞吐量低于 100 Mbps 或延迟较高的网络。由于这个原因或者其他原因,尝试在广域网上(如 Internet )运行 NDB Cluster 不太可能成功,且在生产环境中不受支持。
NDB Cluster 概述
NDB Cluster 是一种在无共享系统中实现内存数据库集群的技术,说明如下:
- 无共享系统 - 每个节点(管理节点、数据节点、SQL节点)独立拥有内存与存储资源,无共享磁盘或网络存储,彻底消除单点瓶颈
- 低经济成本 - 无共享体系架构使系统能够使用非常便宜的硬件,并且对硬件或软件的具体要求最低
- 内存型数据库 - 数据默认完全驻留内存,支持毫秒级点查询,仅在必要时异步持久化至磁盘,满足实时性严苛场景需求
- 性能高 - 专为高可用、低延迟、高并发写入场景设计
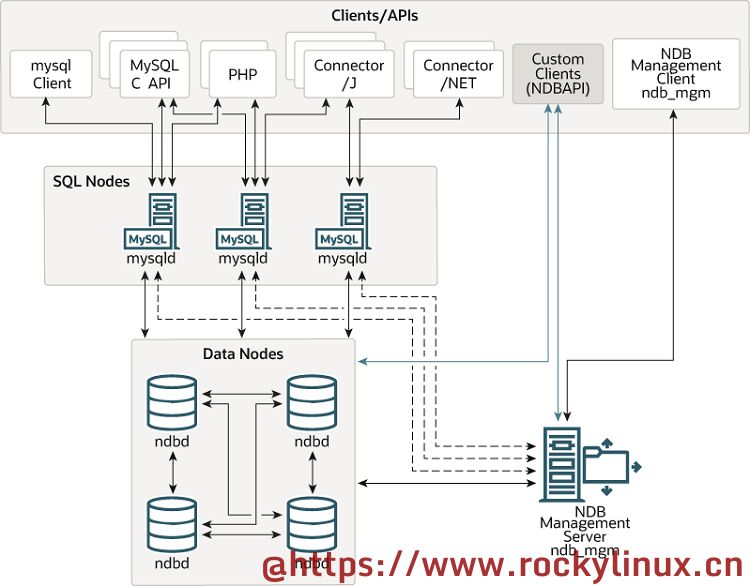
需要注意的是,在许多语境中,"节点(node)" 一词都被用来表示计算机,但是在讨论 NDB Cluster 时,它指的是一个进程,这意味着:
- 可以在一台计算机上运行一个或多个节点
- 对于运行一个或多个集群节点的计算机而言,常用 "集群主机" 这个术语进行表达
集群中节点的三种类型
- 管理节点 - 此类节点用来管理 NDB 集群内的其他节点,执行的功能包括提供配置数据、启动和停止节点以及运行备份等。由于该节点类型管理其他节点的配置,因此 应先启动该类型的节点,而不是其他节点
- SQL 节点(有时也称 API 节点) - 用来访问节点数据的节点。对于 NDB Cluster 而言,一个 SQL 节点就是一个使用 NDB 存储引擎的传统 MySQL 服务器
- 数据节点 - 顾名思义,用来存储集群数据的节点。通常而言,为了提供足够的冗余以及实现高可用,该类型的节点通常需要至少 2 个(换言之,至少需要 2 台计算机来实现)
在启动 NDB Cluster 时,必须首先启动管理节点,然后是数据节点,最后才是任意数量的 SQL 节点。
最小化的集群环境
您至少需要 4 台计算机才能组建一个最小化的集群环境:
- 管理节点(mgmd)
- SQL 节点(mysqld)
- 数据节点 A (ndbd)
- 数据节点 B (ndbd)
核心概念
事件日志(Event logs):NDB Cluster 会按照类别(如 startup、shutdown、errors、checkpoints 等)、优先级以及严重程度来记录各种各样的事件。事件日志主要有两个大类:
- 集群日志(Cluster log) - 用来记录整个集群中所有需要报告的事件,适合绝大多数人进行查阅
- 节点日志(Node log) - 为每个单独的节点单独保留的日志,适用于开发者在进行应用开发以及调试时查阅
检查点(Checkpoint):通常而言,当数据被保存到磁盘上时,人们会说 "数据已到达了一个检查点"。对于 NDB Cluster 而言,检查点是指所有已提交的事务都已存储在磁盘上的某一特定时间点。有两种类型的检查点一起协同工作:
- LCP (Local Checkpoint,本地检查点) - 这是一个仅针对单个节点的检查点;然而,集群中的所有节点都会或多或少同时进行 LCP 操作。LCP 通常每隔几分钟就会发生一次,具体间隔时间存在差异,取决于节点存储的数据量、集群活动水平及其他因素。NDB 8.4 部分支持 LCP,在某些情况下 LCP 能显著提高性能
- GCP (Global Checkpoint,全局检查点) - 每间隔几秒就会发生 GCP 操作,此时所有节点的事务将被同步,且 Redo log 会被刷新到磁盘
传输器(Transporter) - 在 MySQL NDB Cluster 中,使用 "传输器" 一词来指代数据节点之间所采用的数据传输机制。MySQL NDB Cluster 8.4 支持三种此类机制,具体如下:
- 使用以太网上的 TCP/IP 进行连接 - NDB Cluster 中所有节点之间连接的默认传输机制
- 直连式 TCP/IP 进行连接 - 使用此类机制,可提升数据节点之间整体的效率
- 使用共享内存(Shared memory,SHM)进行连接 - 将信号写入到内存当中而不是通过套接字进行传输,可消除高达 20% 的 TCP 连接开销,从而提升性能










