
概述
本章,您将了解 MySQL NDB Cluster 中的复制技术。
在常规社区版的 MySQL Server 中介绍过复制技术,参阅以前的文章 《Redis进阶篇04 — 复制技术(一)MySQL》。
NDB Cluster 复制
在常规社区版的 MySQL Server 中,我们把复制的操作以及数据的来源称为 Source server,把数据的接收服务器称为 Replica server。
在文章《MySQL Cluster篇01 — 概述》 中提到了 InnoDB 存储引擎与 NDB 存储引擎的对比:
| 特性 | InnoDB(MySQL 8.4) | NDB 8.4 |
|---|---|---|
| MySQL 服务器版本 | 8.4 | 8.4 |
| 存储限制 | 64TB | 128TB |
| 外键约束 | 支持 | 支持 |
| 事务 | 所有标准类型 | READ COMMITED 隔离级别 |
| MVCC | 支持 | 不支持 |
| 数据压缩 | 支持 | 不支持 |
| 大行支持机制(大于 14K) | 对 VARBINARY、VARCHAR、BLOB和 TEXT 列的支持 | 仅支持 BLOB 和 TEXT 列(使用这些类型存储大量数据可能会降低 NDB 性能) |
| 复制技术 | 支持异步复制和半同步复制 | 在 NDB 集群内部的自动同步复制;NDB 集群与 NDB 集群之间使用异步复制(不支持半同步复制) |
| ... | ... | ... |
NDB Cluster 支持异步复制,通常会被简称为 "复制"。尽管一个 NDB Cluster 已经可以实现高可用,但是可以利用复制技术将高可用提高到最大(也是最好的),如下图所示:
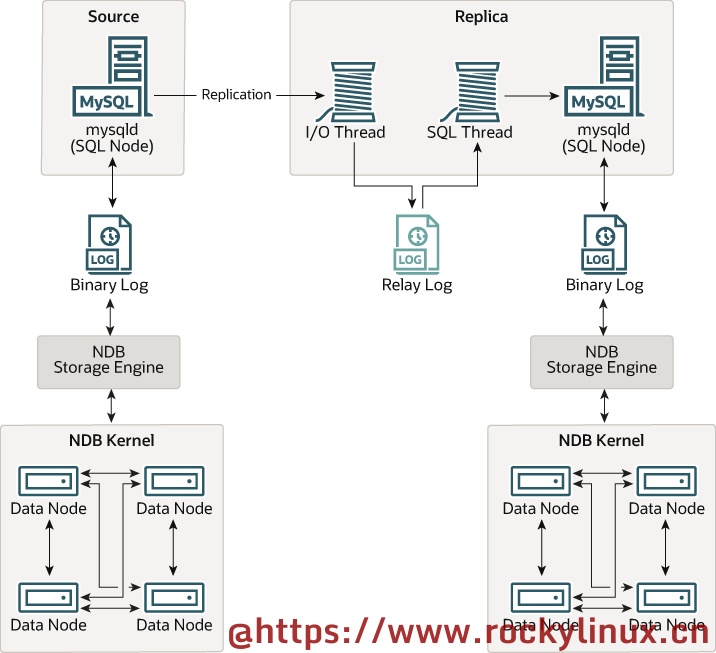
在这种方案中,复制的过程是:
- 记录一个 source cluster 的连续状态并将其保存到另外一个 replica cluster 中。此过程通过一个叫做 NDB binary log injector 的特殊线程来完成,该线程运行于每个 SQL 节点中并生成二进制日志(binlog)
- 我们把左边 Source Cluster 中的 SQL Node 和右边 Replica Cluster 的 SQL Node 称为复制节点,它们之间的数据流或通信线路称为 复制通道
缩写符号
为了方便说明,我们特地使用一些特殊的符号来代表一些含义,如下表格所示:
| 符号缩写 | 含义 |
|---|---|
| S | source cluster 的主复制源 |
| S' | 次复制源 |
| R | replica cluster 的主副本 |
| R' | 次副本 |
| C | 主复制通道 |
| C' | 次复制通道 |
| Shell S > | 要在 source cluster 上发出的 shell 命令 |
| MySQL S > | 要在 source cluster 上向单个 SQL 节点发出的 MySQL 命令 |
| MySQL S* > | 要在 source cluster 上向所有 SQL 节点发出的 MySQL 命令 |
| Shell R > | 要在 replica cluster 上发出的 shell 命令 |
| MySQL R > | 要在 replica cluster 上向单个 SQL 节点发出的 MySQL 命令 |
| MySQL R* > | 要在 replica cluster 上向所有 SQL 节点发出的 MySQL 命令 |
NDB Cluster 复制的一般要求
- Source Cluster 中 SQL 节点数量与 Replica Cluster 中 SQL 节点数量一样
- Source Cluster 中需要将所有 SQL节点 的 /etc/my.cnf 修改,将二进制日志的格式修改为 ROW,即 "[mysqld]" 下面的
binlog-format=ROW。同样 Replica Cluster 中所有 SQL 节点也是一样的要求 - 不管是 Source Cluster 中的 SQL 节点,还是 Replica Cluster 中的 SQL 节点,它们 /etc/my.cnf 文件中的 server-id 参数值必须都是唯一的(不能重复)
- 不管是 Source Cluster 中的三个节点类型,还是 Replica Cluster 中的三个节点类型,它们必须使用相同的软件版本
循环复制
NDB Cluster 的复制支持循环复制。要满足循环复制的要求,需要:
- Source Cluster 中 SQL 节点数量与 Replica Cluster 中 SQL 节点数量一样
- 所有 SQL 节点在 /etc/my.cnf 中都必须启用这个参数,即 "[mysqld]" 下面的
log-replica-updates=1
循环复制如下图所示(所有源作为副本所形成的循环复制):
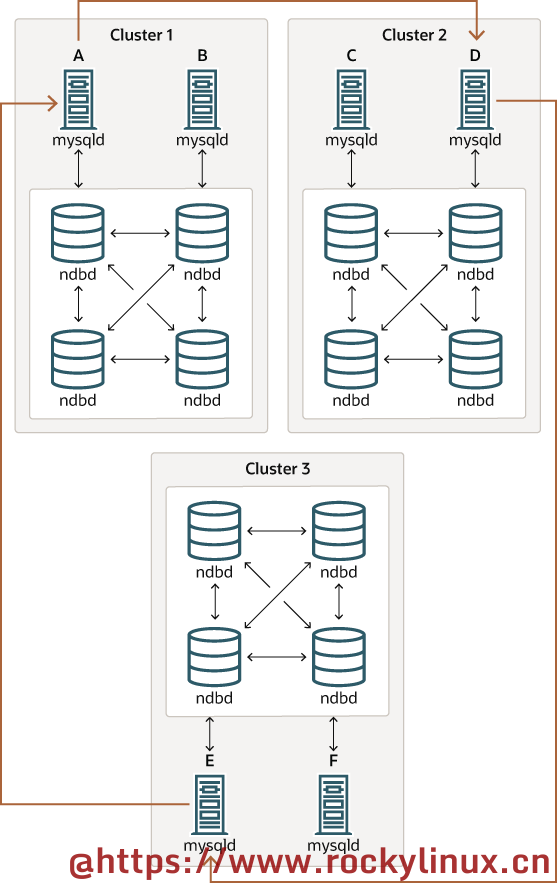
说明如下:
-
这里有编号为 1、2、3 的三个集群,其中 Cluster 1 充当 Cluster 2 的复制源;Cluster 2 充当 Cluster 3 的复制源,Cluster 3 充当 Cluster 1 的复制源,形成了一个循环
-
在该示例中,每个集群都有 2 个 SQL 节点, A 和 B 属于 Cluster 1;C 和 D 属于 Cluster 2;E 和 F 属于 Cluster 3
-
由图中的复制线(浅黄色箭头线)可知,Cluster 1 中 的 A SQL 节点复制到 Cluster 2 D SQL 节点;Cluster 2 中 的 D SQL 节点复制到 Cluster 3 E SQL 节点;Cluster 3 中的 E SQL 节点复制到 Cluster 1 A SQL节点
对于下面这种循环复制,目前处于未经广泛测试的实验阶段:
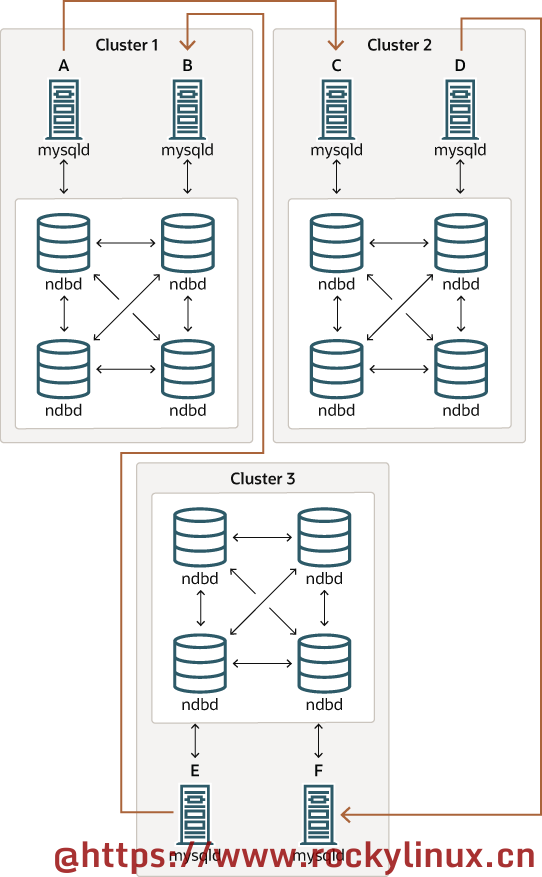
与复制相关的表
这些是专用于 NDB Cluster 复制的表:
-
ndb_apply_status 表 - 记录 source 到 replica 操作的表。表的定义为:
CREATE TABLEndb_apply_status(server_idINT(10) UNSIGNED NOT NULL,epochBIGINT(20) UNSIGNED NOT NULL,log_nameVARCHAR(255) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,start_posBIGINT(20) UNSIGNED NOT NULL,end_posBIGINT(20) UNSIGNED NOT NULL, PRIMARY KEY (server_id) USING HASH ) ENGINE=NDBCLUSTER DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; -
ndb_binlog_index 表 - 复制时使用该表存储 binlog 的索引数据。表的定义为:
CREATE TABLEndb_binlog_index(PositionBIGINT(20) UNSIGNED NOT NULL,FileVARCHAR(255) NOT NULL,epochBIGINT(20) UNSIGNED NOT NULL,insertsINT(10) UNSIGNED NOT NULL,updatesINT(10) UNSIGNED NOT NULL,deletesINT(10) UNSIGNED NOT NULL,schemaopsINT(10) UNSIGNED NOT NULL,orig_server_idINT(10) UNSIGNED NOT NULL,orig_epochBIGINT(20) UNSIGNED NOT NULL,gciINT(10) UNSIGNED NOT NULL,next_positionbigint(20) unsigned NOT NULL,next_filevarchar(255) NOT NULL, PRIMARY KEY (epoch,orig_server_id,orig_epoch) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; -
ndb_replication 表 - 用于复制时的冲突检测和冲突解决,必须由用户进行创建和维护。该表中的每一行数据对应于一张正在复制的表。在简单的单向复制中(源 → 副本),该表创建的位置位于副本。在双向复制中(A ⇄ B),该表创建的位置位于参与复制的所有源(A 和 B)。官方对表的定义如下:
CREATE TABLE mysql.ndb_replication ( db VARBINARY(63), table_name VARBINARY(63), server_id INT UNSIGNED, binlog_type INT UNSIGNED, conflict_fn VARBINARY(128), PRIMARY KEY USING HASH (db, table_name, server_id) ) ENGINE=NDB PARTITION BY KEY(db,table_name);- db 字段 - 包含要复制的表的库名称,支持通配符 _ 和 %(也就是 SQL 当中的 like 语法通配符,_ 表示匹配任意一个字符,% 表示匹配任意字符)
- table_name - 要复制的表的名称,支持通配符 _ 和 %
- server_id - 即 SQL 节点 /etc/my.cnf 中 server-id 参数的值,支持通配符 _ 和 %
- binglog_type - 二进制日志的类型。见下表
- conflicat_fn - 冲突解决函数。可以是 NDB$OLD()、NDB$MAX()、NDB$MAX_DELETE_WIN()、NDB$EPOCH()、NDB$EPOCH_TRANS()、NDB$EPOCH2()、NDB$EPOCH2_TRANS()、NDB$MAX_INS()、NDB$MAX_DEL_WIN_INS() 中的其中一个。null 表示不使用冲突解决。
binlog_type 的值说明:
| 值 | 说明 |
|---|---|
| 0 | 使用服务器默认值 |
| 1 | 不在二进制日志中记录此表(效果等同于 sql_log_bin = 0,但仅适用于一个或多个指定表) |
| 2 | 仅记录已更新的属性;将这些更新记录为 WRITE_ROW 事件 |
| 3 | 记录完整行数据,即使该行未被更新(MySQL 服务器默认行为) |
| 6 | 使用已更新的属性,即使值未发生实际变化 |
| 7 | 记录完整行数据,即使没有任何值被更改;将更新记录为 UPDATE_ROW 事件 |
| 8 | 将更新记录为 UPDATE_ROW 事件;"前镜像"(before image)仅记录主键列,"后镜像"(after image)仅记录已更新的列(效果等同于 --ndb-log-update-minimal,但仅适用于一个或多个指定表) |
| 9 | 将更新记录为 UPDATE_ROW6 事件;"前镜像" 仅记录主键列,"后镜像" 记录除主键列外的所有列 |
ndb_binglog_index 和 ndb_apply_status 这两个表位于 mysql 这个库中,通常不需要用户创建且维护它们,因为它们都是由 NDB binary log injector 线程来维护。该线程直接从 NDB 存储引擎中接收事件。该线程会捕获集群中所有数据事件,并将数据的更改、插入、删除都记录在 ndb_binglog_index 表中。之后,副本的 I/O 线程会将这些事件从源端的二进制日志传输到副本的中继日志中。
show binglog events; 或 show engine ndb status;启用双通道复制
我们假设您的 Source Cluster 中各个节点类型能够正常通信且完成了最基本的配置,同理,您的 Replica Cluster 也是一样。NDB Cluster 版本统一使用 8.4.8 TLS,操作系统统一使用 Rocky Linux 8.10。
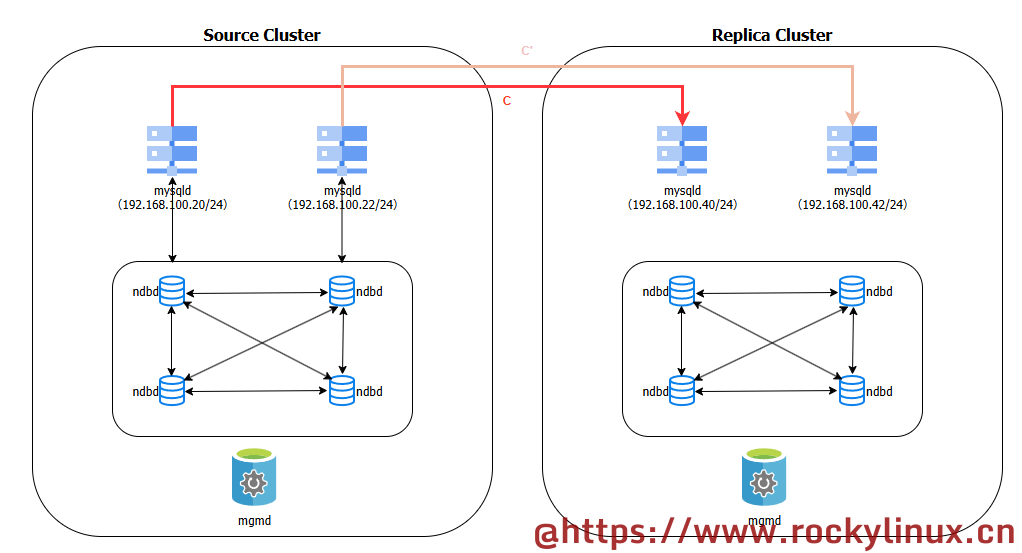
所谓双通道复制,指的是双线路热备,其标准架构是这样的:
- Source Cluster 必须有两个 SQL 节点(S 和 S')
- Replica Cluster 必须有两个 SQL 节点(R 和 R')
- 主复制通道 C 指的是 S → R
- 次复制通道 C' 指的是 S' → R'
同一时间只启动一条通道,防止数据重复。
Source Cluster 基本信息
| 节点类型 | Server ID | Node ID | 内存 | CPU | 磁盘大小 | IP 地址 |
|---|---|---|---|---|---|---|
| 管理节点(mgmd) | 1 | 4GB | 1 core | 50GB | 192.168.100.10/24 | |
| 数据节点 A * (ndbd) | 2 | 4GB | 1 core | 50GB | 192.168.100.12/24 | |
| 数据节点 B(ndbd) | 3 | 4GB | 1 core | 50GB | 192.168.100.14/24 | |
| 数据节点 C(ndbd) | 4 | 4GB | 1 core | 50GB | 192.168.100.16/24 | |
| 数据节点 D(ndbd) | 5 | 4GB | 1 core | 50GB | 192.168.100.18/24 | |
| SQL 节点 1 (mysqld) | 6 | 6 | 4GB | 1 core | 50GB | 192.168.100.20/24 |
| SQL 节点 2 (mysqld) | 7 | 7 | 4GB | 1 core | 50GB | 192.168.100.22/24 |
Replica Cluster 基本信息
| 节点类型 | Server ID | Node ID | 内存 | CPU | 磁盘大小 | IP 地址 |
|---|---|---|---|---|---|---|
| 管理节点(mgmd) | 11 | 4GB | 1 core | 50GB | 192.168.100.30/24 | |
| 数据节点 E * (ndbd) | 12 | 4GB | 1 core | 50GB | 192.168.100.32/24 | |
| 数据节点 F(ndbd) | 13 | 4GB | 1 core | 50GB | 192.168.100.34/24 | |
| 数据节点 G(ndbd) | 14 | 4GB | 1 core | 50GB | 192.168.100.36/24 | |
| 数据节点 H(ndbd) | 15 | 4GB | 1 core | 50GB | 192.168.100.38/24 | |
| SQL 节点 3 (mysqld) | 16 | 16 | 4GB | 1 core | 50GB | 192.168.100.40/24 |
| SQL 节点 4 (mysqld) | 17 | 17 | 4GB | 1 core | 50GB | 192.168.100.42/24 |
图例说明
见下图所示:
步骤说明
步骤一:配置 Replica Cluster 中的所有 SQL 节点
在 Replica Cluster 中,所有 SQL 节点的 /etc/my.cnf 都需要配置,简单的示例配置如下:
Shell > vim /etc/my.cnf
[mysqld]
ndbcluster
binlog-format=ROW
# 每个SQL节点的标识符都不同
server-id=16
default-storage-engine=NDBCLUSTER
[mysql_cluster]
# 指向 replica cluster 的管理节点,我们这里都只有一个
ndb-connectstring=192.168.100.30
replica-allow-batching=1
ndb-replica-batch-size=2097152
ndb-replica-blob-write-batch-bytes=2097152Replica Cluster 中的所有 SQL 节点都执行以下操作:
Shell > /usr/local/mysql/support-files/mysql.server stop
Shell > /usr/local/mysql/support-files/mysql.server start步骤二:配置 Source Cluster 中的所有 SQL 节点
在 Source Cluster 中,所有 SQL 节点的 /etc/my.cnf 都需要配置,简单的示例配置如下:
Shell > vim /etc/my.cnf
[mysqld]
ndbcluster
binlog-format=ROW
# 每个SQL节点的标识符都不同
server-id=6
default-storage-engine=NDBCLUSTER
[mysql_cluster]
# 指向 Source Cluster 的管理节点,我们这里都只有一个
ndb-connectstring=192.168.100.10
replica-allow-batching=1
ndb-replica-batch-size=2097152
ndb-replica-blob-write-batch-bytes=2097152Source Cluster 中的所有 SQL 节点都执行以下操作:
Shell > /usr/local/mysql/support-files/mysql.server stop
Shell > /usr/local/mysql/support-files/mysql.server start步骤三:创建用于复制且拥有复制特权的账户
SQL 语法如下:
MySQL S > create user 'replica_user'@'replica_host' identified by 'replica_password' ;
MySQL S > grant replication slave on *.* to 'replica_user'@'replica_host' ;这里的 replica_user 替换为具体的账户,replica_host 替换为复制副本的主机名或 IP 地址,replica_password 替换为账户的密码,replication slave 替换为具体的特权。
创建具体的账户:
MySQL S(192.168.100.20)> create user 'myreplica'@'%' identified by '9745270' ;
MySQL S(192.168.100.20)> grant replication slave on *.* to 'myreplica'@'%' ;步骤四:在 Replica Cluster 中配置双通道
注:从 Mysql Server 8.0.13 与 Mysql NDB Cluster 8.0.13 开始,Mysql NDB Cluster 采用与 Mysql Server 8.0 系列版本相同的发布策略。从 Mysql Server 8.0.23 开始,不再以 master 和 slave 来区分主从,而是使用 source 和 replica 来替代,这也造成了部分语法的关键字会不一样。
在 MySQL NDB Cluster 8.0.23 之前的版本,可使用的语法:
MySQL > change master to
master_host='source_host',
master_port=source_port,
master_user='replica_user',
master_password='replica_password';从 MySQL NDB Cluster 8.0.23 开始,您还可以使用如下语法:
MySQL > change replication source to
source_host='source_host',
source_port=source_port,
source_user='replica_user',
source_password='replica_password';有关 change replication source to ... 的完整语法,请参考 这里。
对 SQL 节点 3 (192.168.100.40) 配置主复制通道且启动主复制通道:
# 配置主复制通道
MySQL R(192.168.100.40)> change replication source to
source_host='192.168.100.20',
source_port=3306,
source_user='myreplica',
source_password='9745270',
source_auto_position=1
for channel 'primary_channel' ;
# 启动主复制通道
MySQL R(192.168.100.40)> start replica for channel 'primary_channel' ;
# 查询主复制通道状态
MySQL R(192.168.100.40)> show replica status for channel 'primary_channel' \G;
...
Replica_IO_Running: Yes
Replica_SQL_Running: Yes
...对 SQL 节点 4 (192.168.100.42) 配置次复制通道但不启动:
MySQL R'(192.168.100.42)> change replication source to
source_host='192.168.100.22',
source_port=3306,
source_user='myreplica',
source_password='9745270',
source_auto_position=1
for channel 'secondary_channel' ;步骤五:手动创建冲突解决表
MySQL R (192.168.100.40) > CREATE TABLE mysql.ndb_replication (
db VARBINARY(63),
table_name VARBINARY(63),
server_id INT UNSIGNED,
binlog_type INT UNSIGNED,
conflict_fn VARBINARY(128),
PRIMARY KEY USING HASH (db, table_name, server_id)
) ENGINE=NDB PARTITION BY KEY(db,table_name);









