
概述
本章,您将学习到 MySQL 的索引知识,内容包括:
- 索引基本原理
- 磁盘与索引的关系
- 索引的使用语法与原则
篇幅限制,本篇介绍索引的基本原理以及磁盘与索引的关系,作为一般性质的数据库使用人员,大致了解即可,不需要死记硬背。
索引基本原理
当一条复杂的 SQL 执行过慢时,我们通常从这方面去排查:
- 硬件的性能瓶颈。 使用如
top、htop、vmstat等命令查看资源的占用情况 - MySQL 配置文件的参数调整
- join 关联的表太多
- 索引失效
一条标准 DQL 语句的格式如下:
select 查询列表 from 表1 [join type] join 表2
on 连接条件 where 筛选条件
group by 分组字段 having 分组筛选 order by 排序字段
limit 起始索引,要显示的条目数;MySQL 的执行顺序为:
- 找到表1(
from 表1) - 关联表2(
[join type] join) - 关联时的连接条件(
on 连接条件) - 数据过滤(
where 筛选条件) - 分组以及分组筛选(
group by 分组字段 having 分组筛选) - 显示的字段(
select 查询列表) - 按照显示的字段进行排序(
order by 排序字段) - 分页查询(
limit 起始索引,要显示的条目数;)
了解索引
索引(Index): 提高数据查询效率的一种数据结构。MySQL 除了保存用户存储的数据之外,还维护着特定查找算法的指向表中数据的数据结构,即索引。
Q:为什么需要索引?有无优缺点?
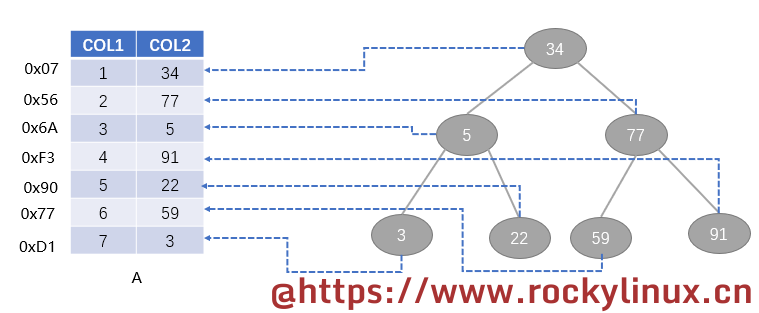
举例来说,这里有一张 A 表,左边的 0x07 是行数据在磁盘上的物理地址(请注意!表上面虽然是相邻的数据,但实际在磁盘上面它们不一定是相邻的),COL1 和 COL2 是表的字段名称,其下面则是具体的行数据:
COL1 COL2
0x07 | 1 | 34 |
0x56 | 2 | 77 |
0x6a | 3 | 5 |
0xf3 | 4 | 91 |
0x90 | 5 | 22 |
0x77 | 6 | 59 |
0xd1 | 7 | 3 |在没有添加索引之前,查询数据是通过从上到下一行一行的遍历,即全表扫描。
当我要查询 COL2 列为 34 的这行数据时(select * from A where COL2=34;),由于查询的行数据在第一行,因此查询速度很快。如果我要查询 COL2 列为 3 的这行数据(select * from A where COL2=3;),由于查询的行数据位于最后一行且查询时是全表扫描,这影响了查询的速度。试想下,生产环境下单表都是十几万行甚至更多的数据,如果每次查询都是全表扫描,查询速度很明显会非常慢。
有了索引后,可对 COL2 这个字段建立索引。前面提到,索引是一种数据数据。我们以简单的二叉树(二叉树:子节点每次最多有两个分叉且有左右之分,整个结构呈现出一个倒挂的树状结构,于是称二叉树)为例来讲解。
- 第一个 34 是它的根节点
- 77 比 34 大,于是放在 34 的右下边;5 比 34 小,所以放在 34 的左下边
- 91 比 34 大,放在其右下边,但是由于最多有两个分叉,又和 77 比较,比 77 大,放在它的右下边。以此类推,就形成了如下所示的一个倒挂的分叉的树状结构。
若要查询 COL2 为 3 的这行数据,这种数据结构首先从根节点开始查找,3 比 34小,就来到 34 的左下边进行比较,3 又比 5 小,来到5的左下边进行比较,最终找到了 3 。找到了3,就可以指向 COL2 为 3 的这行数据。大概就是这个意思。
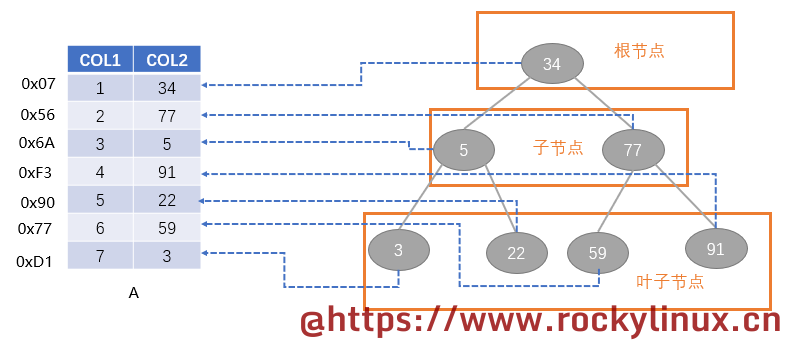
从上面的例子可以简单归纳二叉树索引的优势与劣势:
| 优势 | 劣势 |
|---|---|
| 提升查询的效率与速度 | 索引也需要额外的磁盘空间,当有大量索引时,索引文件的大小可能比实际的数据文件更加大 |
| 对数据进行有规律的重新排序 | 当对表中的数据进行插入(insert)、删除(delete)和更新(update)时,索引也需要动态维护,这降低了数据的维护速度 |
索引的支持与划分
| 索引类型 | InnoDB 存储引擎 | MyiSAM 存储引擎 | Memory 存储引擎 |
|---|---|---|---|
| BTREE/B+TREE | √ | √ | √ |
| HASH 索引 | √ | ||
| R-TREE | √ | √ | |
| Full-Text 索引 | √ | √ |
- BTREE/B+TREE:B 树,最常见的索引类型
- HASH 索引:仅 Memory 存储引擎支持
- R-TREE:空间索引,用在空间数据类型上
- Full-Text 索引:全文索引,一种特殊的数据索引类型,用于全文检索
这是 MySQL 中索引的具体划分:
- 从数据结构进行划分
- BTREE/B+TREE
- HASH 索引
- R-TREE
- Full-Text 索引
- 从物理存储进行划分
- 聚集索引
- 非聚集索引(也称二级索引、辅助索引)
- 按照字段特征进行划分
- 主键索引
- 唯一索引
- 普通索引
- 全文索引
- 前缀索引
- 按照字段个数进行划分
- 单列索引(也称单值索引)
- 联合索引(也称复合索引、组合索引、多列索引、多值索引)
BTREE/B+TREE
BTREE 最早由德国科学家鲁道夫·拜尔(Rudolf Bayer,1939年5月7日 - ) 等人于 1972 年在论文 《Organization and Maintenance of Large Ordered Indexes》中提出,此人因发明数据结构而出名:
- B 树(与 Edward M.McCreigh合作)
- UB 树(与 Volker Markl 合作)
- 红黑树
BTREE(B 树):多路平衡搜索数,类似于普通的二叉树,但 BTREE 允许每个节点有更多的子节点。
M 叉的 BTREE 有如下特征:
- 节点分叉限制 - 每个节点最多包含 m 个 "孩子" (分叉数)
- 非根/叶节点约束 - 除根节点与叶子节点外,每个节点至少有 [celi(m/2)] 个 "孩子"(celi 表示向上取整)
- 根节点要求 - 至少有两个 "孩子"
- 叶子节点平衡性 - 所有叶子节点位于同一层,确保树高平衡
- 非叶子节点结构 - 每个非叶子节点由 n 个 key 和 n+1 个指针组成,其中 [celi(m/2)-1] <= n <= m-1
以五叉 BTREE 为例,根据其特征可知:
- 每个节点最多包含 5 个分叉
- 除根节点与叶子节点外,每个节点至少有 3 个 "孩子"
- 根节点至少有两个 "孩子"
- 根据公式可知, 2 =< n <=4,当 n > 4 时,中间元素分裂到父节点,同时两边节点也开始分裂
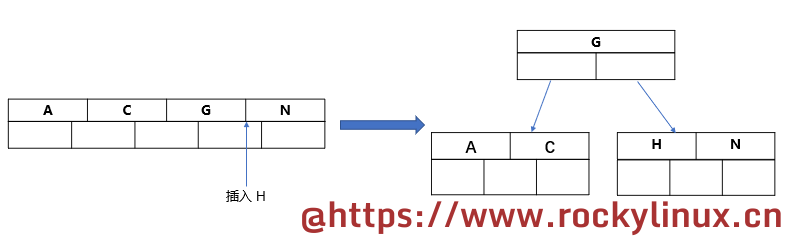
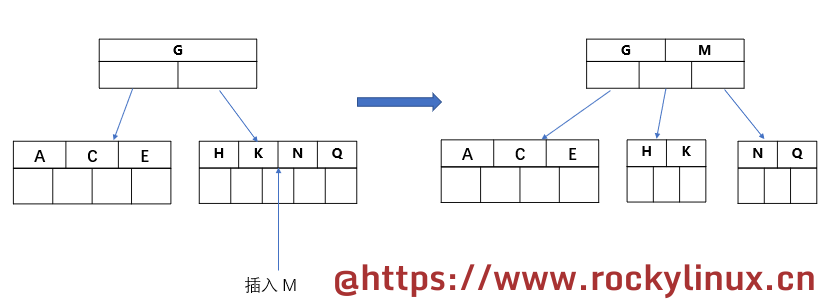
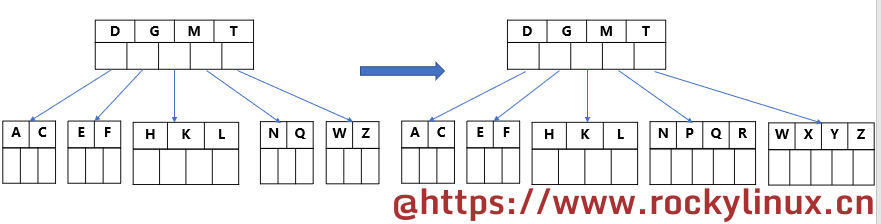
当要插入的数据为 "C N G A H E K Q M F W L T Z D P R X Y S" 时,其分裂过程如下:
-
过程1
插入前 4 个数据 "C N G A"。C 与 N 比较,C 在前面,N 在后面。插入 G,与 C 比较,在 C 后面,与 N 比较,在 N 的前面;插入 A,排在最前面,这四个数据组成了 4 个 key 或者元素。

-
过程2
插入 H,由于此时 key 的数量大于 4,于是,中间的 G 元素分裂成父节点,变成了这样:
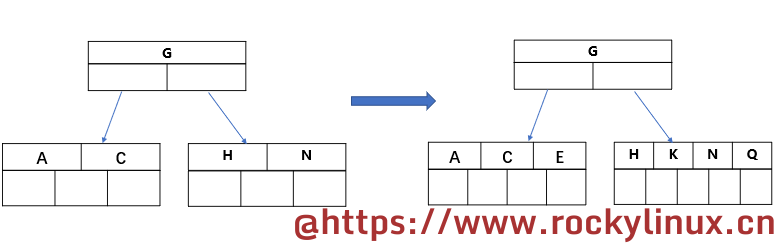
-
过程3
插入 E K Q,它们都与 G 进行比较,不需要进行另外的分裂。根据前面所述,这里的根节点有 1 个 key 以及 2 个指针(表格空白处),所谓指针,就是与根节点进行比较,比根节点大的走右边,小的走左边,其指向的是数据块。
-
过程4
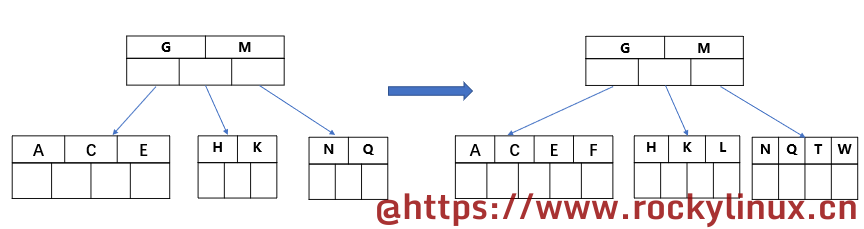
插入 M,M 比 G 大,此时最右边的 key 超过了 4 个,中间元素 M 分裂到父节点,同时两边的节点也开始分裂
-
过程5
插入 F W L T,元素或 key 的个数小于等于 4,不需要另外的分裂
-
过程6
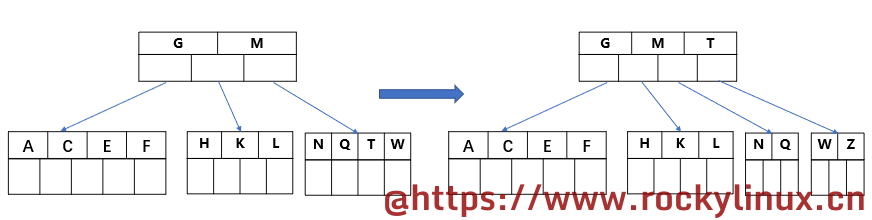
插入 Z ,元素个数超过 4 ,中间元素 T 分裂到父节点,同时两边的节点也开始分裂
-
过程7
插入 D,此时超过了 4 个元素/key,中间元素 D 分裂到父节点,同时两边的节点也开始分裂
-
过程8
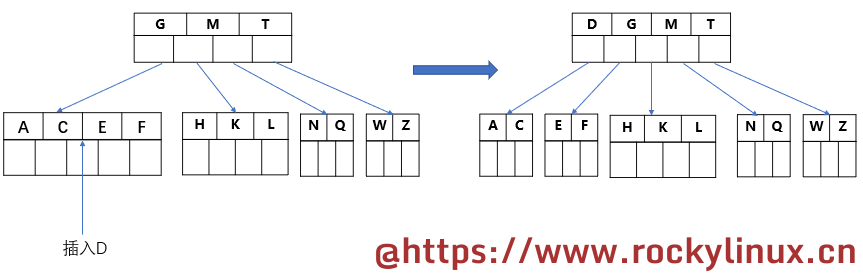
插入 P R X Y,没有超过 4 个元素/key,不需要分裂
-
过程9
最后插入 S,中间元素 Q 分裂到父节点,此时父节点的元素/key数量达到了 5,中间元素 M 向上分裂到父节点。最终呈现如这样的结构:
此时节点的分裂全部完成,可以看到,对于海量的数据,BTREE 的效率比二叉树高了很多。同样的数据,二叉树的层次深度相比 BTREE 更深一些,更深则意味着经过的数据块更多,也就更加耗时间。

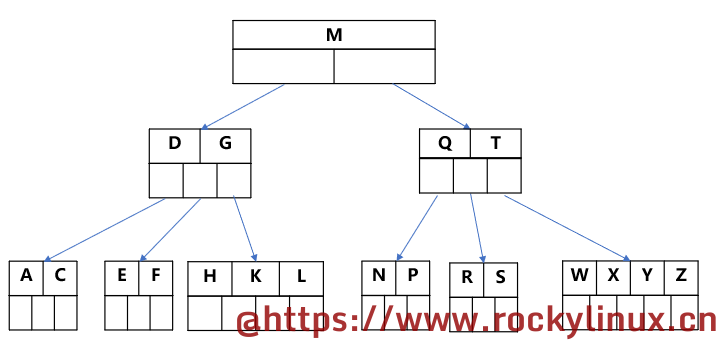
经典 B+TREE
经典 B+TREE 是 BTREE 的一种变体,主要区别为:
- N 叉 B+TREE 每个节点最多可含有 n 个key,而 BTREE 则最多包含 n-1 个key
- 经典 B+TREE 的叶子节点保存所有的完整的 key 信息,按照 key 的大小顺序排序
- 所有非叶子节点都可以看作 key 的索引部分,不存储数据信息
- 经典 B+TREE 所有的叶子节点存放所有的数据信息,但 BTREE 的数据存放与节点挂钩
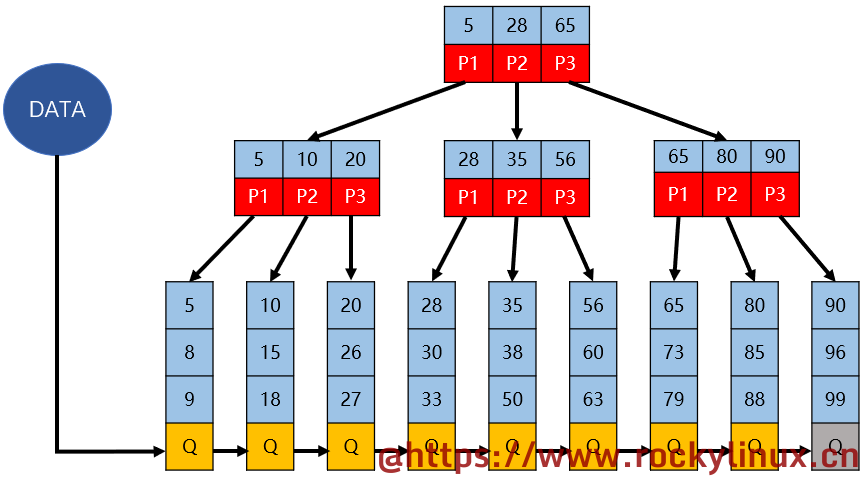
MySQL 中的 B+TREE
MySQL 中的 B+TREE 则是在经典 B+TREE 的基础上进一步优化,在经典 B+TREE 基础上增加了一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的 B+TREE,提高区间访问的性能(即方便范围查询)。
了解磁盘与索引的关系
机械硬盘的物理结构
如下图所示:

其中最核心的是就两个东西——磁头与磁盘(盘片)。
说到机械硬盘,会涉及到这些专有的名词:
- 盘片(platter)
- 磁头(head)
- 磁道(track)
- 扇区(sector)
- 柱面(cylinder)
一块机械硬盘一般会有多个盘片 ,每个盘片包含两个面,每个盘面都有一个对应的读写磁头。如下面的这块硬盘,它有9个物理盘片和10个物理磁头:

机械硬盘工作时,主轴电机驱动盘片高速旋转(通常为 7200 转/分),所有的磁头通过磁头臂连接在同一根轴上,即所有的磁头在工作时都做着相同的「动作」进行数据的读或写。机械硬盘工作期间,磁头与盘片间隙仅几纳米,震动可能导致磁头撞击盘片,造成物理损坏或数据丢失。当断电后,磁头会停在磁头停泊区。
一个盘面被划分为若干个同心圆环,我们将每个同心圆环称为 磁道 。最外圈为 0 磁道,存储数据一般是从外向内存储。请注意!磁道与磁道之间并不是紧紧挨着的。
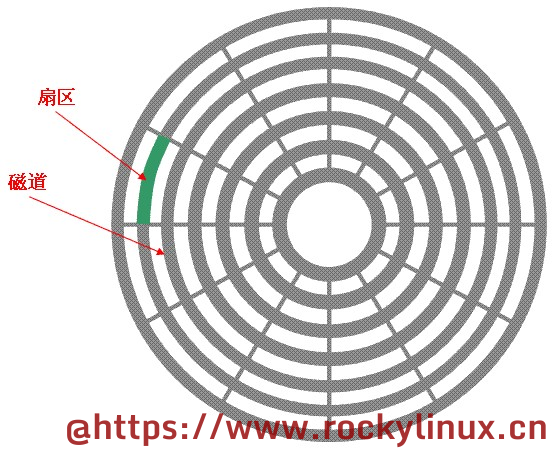
每个同心圆环中被划分为若干个相同的弧段,它们被称为 物理扇区,物理扇区是硬盘存储的最小物理单位。物理扇区的大小由厂商来决定,早期是 512 字节,现在的物理扇区普遍都是 4K 大小。
所有盘面上具有相同磁道编号所构成的圆柱结构,称为 柱面。当一个磁道写满数据后,就在该柱面下的下一个磁道继续写,直到把该柱面写满为止,才移动下一个柱面的磁道。数据的读/写都是按照柱面进行的,这是因为所有的物理磁头都是做着相同的「动作」进行读/写数据

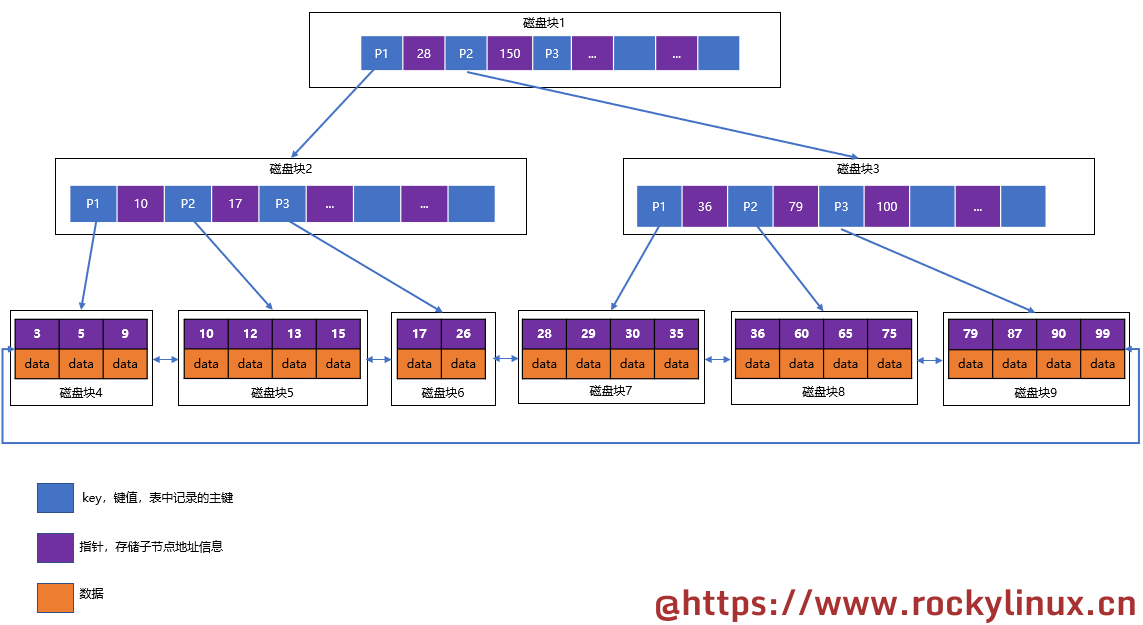
文件系统中的块与簇
由于物理扇区容量小而且数量众多,操作系统在寻址时比较困难,于是将相邻的扇区组合在一起,形成一个打包的整体,在 Windows 的 NTFS 文件系统中,这个整体被称为 簇(cluster);在 GNU/Linux 的 ext4 文件系统中,这个整体称为 块(block)。不同的文件系统对这个打包的整体在名称定义上可能是不同的。
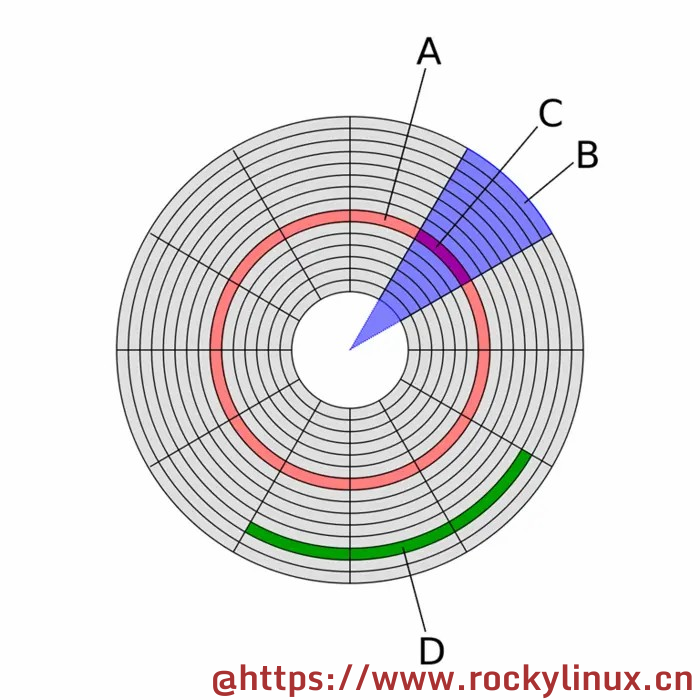
如下图所示,A 称为磁道;B 称为扇面;C 称为物理扇区; D 称为簇/块:
Q:如何在 Windows 与 GNU/Linux 中查看簇或块的大小?
-
Windows 可以使用命令行——
fsutil fsinfo ntfsinfo 盘符,翻译问题,它会显示「每群集字节数」,其实就是一个簇的大小,通常都是 4096 字节。PS > fsutil fsinfo ntfsinfo D: NTFS 卷序列号 : 0xbd28a757c3d080b6 NTFS 版本 : 3.1 LFS 版本 : 2.0 总扇区 : 789,844,622 (376.6 GB) 总群集 : 98,730,577 (376.6 GB) 空余群集 : 49,431,124 (188.6 GB) 总保留群集 : 1,024 ( 4.0 MB) 用于存储备用的保留 : 0 ( 0.0 KB) 每扇区字节数 : 512 每物理扇区字节数 : 4096 每群集字节数 : 4096 (4 KB) ←← 这里 每 FileRecord 分段字节数 : 1024 每 FileRecord 分段群集数 : 0 Mft 有效数据长度 : 36.00 MB Mft 开始 Lcn : 0x00000000000c0000 Mft2 开始 Lcn : 0x0000000000000002 Mft 区域开始 : 0x00000000000c2400 Mft 区域结束 : 0x00000000000ce080 MFT 区域大小 : 188.50 MB 最大设备修剪程度计数 : 256 最大设备修剪字节计数 : 0xffffffff 最大卷修剪程度计数 : 62 最大卷修剪字节计数 : 0x40000000 Resource Manager 标识符: B55AC38B-2915-11EC-9314-EE4E3F47346E -
在 GNU/Linux 中,你可以使用命令行——
dumpe2fs -h 设备分区号查看具体的块大小。通常而言也是 4096 字节。Shell > dumpe2fs -h /dev/nvme0n1p2 dumpe2fs 1.45.6 (20-Mar-2020) Filesystem volume name:Last mounted on: / Filesystem UUID: e56b31aa-8425-4e23-8eee-07153ef28273 Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file dir_nlink extra_isize metadata_csum Filesystem flags: signed_directory_hash Default mount options: user_xattr acl Filesystem state: clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 3080192 Block count: 12320512 Reserved block count: 616025 Free blocks: 11381753 Free inodes: 3036703 First block: 0 Block size: 4096 ←← 这里 ...
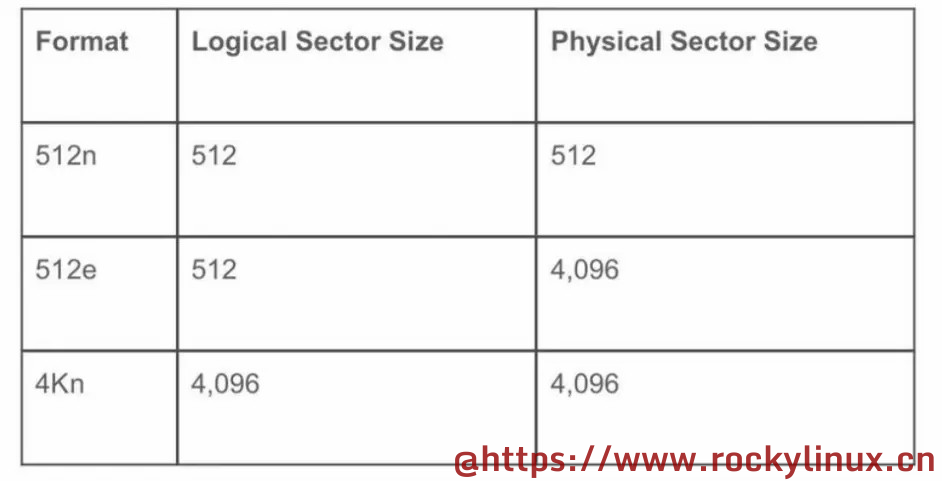
前面提到,最早的物理扇区大小是 512 字节,然而随着机械硬盘容量的不断提高以及性能要求的需要,IDEMA(International Disk Drive Equipment and Materials Association,国际硬盘设备与材料协会) 将每个磁盘的物理扇区从 512 字节修改为 4096 字节,也就是常说的 「4K扇区」,支持这一个标准的硬盘又称为 AF(Advanced Format ,高级格式化)硬盘。
「4K扇区」的标准在 2010 年才完成制定,但是硬件以及大量的软件、数据库存储引擎等等这些依然是以 512 字节的物理扇区进行设计的,为了兼容性,硬盘制造商在 AF 硬盘上集成了转换固件,具有这种转换固件的硬盘又称为 AF 512e 硬盘,「512e」中的 e 表示 emulation (仿真)。除了 AF 512e 硬盘 外,还有一个被称为 AF 4Kn 硬盘,它是指原生 4K 扇区,不存在仿真模拟转换层,通常只在企业级硬盘中才有,而且会有特殊的蓝色 logo 标识在硬盘上。
AF 512e 硬盘的 logo:

AF 4Kn 硬盘的 logo:

对照图如下:
机械硬盘的性能指标
- 寻道时间:它是指计算机发出一个寻址指令后,磁头找到所在柱面磁道所需要的时间,单位为毫秒(ms)。这是磁盘访问中最耗时的部分
- 旋转延迟:等待目标扇区旋转到磁头下方的时间
- 数据传输时间:实际读写数据的时间,取决于数据块大小和磁盘传输速率
顺序读写或者称顺序 I/O,它是指本次 I/O 的初始扇区地址和上一次 I/O 的结束扇区地址是完全连续或者相隔不多的;反之,如果相差较大,则可以算作一次随机 I/O。机械硬盘最让人诟病的地方就是随机读写的速度很慢,这种慢其实是由机械硬盘的物理结构决定的。
索引与磁盘的关系
以 MySQL 的 B+TREE 为例,它对存储数据进行了两个优化:
- 将数据重新排序
- 将数据块相邻
我们可以对索引(Index)给出一个相对完整的定义:索引是提高数据查询效率的一种数据结构,反映在物理磁盘上,其将数据重新排序,使数据所在的物理扇区更加地集中,可最大程度实现顺序读并减少 I/O 的次数,提高查询的速度。
行业中,一个数据结构能否被作为索引,很大程度上取决于查找过程中能否尽可能地减少 I/O 次数。










