
概述
本章,您将学习 MySQL 中的 TCL(Transaction Control Language,事务控制语言)
TCL 的内容包括:
- 了解存储引擎
- 事务的特性(ACID)
- 事务分类
- 事务基础使用与特性控制
- 事务并发产生的问题
- 隔离级别
事务也涉及到底层的各种锁机制,但这部分的内容很多,需要单独再书写一章的内容。
事务(Transaction):事务是 MySQL的一种机制(当然其他的关系型数据库也有),它由一条或者多条 SQL 语句组成,这些成批的 SQL 语句是一个执行单元,它们互相依赖且是一个不可分隔的整体,要么全部执行,要么全部不执行,用来完成某一个业务或事情或功能,保证数据库的完整性或一致性。如果某一事务执行成功,则在该事务中进行的所有数据修改均会被提交,成为数据库中的永久组成部分。如果事务遇到错误且必须取消或回滚,则所有数据修改均被清除。
回滚:把正在执行的操作全部撤销,回到最初的状态。在 Windows 当中安装软件时最容易见到,当安装一个大型软件(如 Adobe 系列)时,如果某一步依赖的环境检查未通过或者发生错误,它会显示——「正在回滚更改」
存储引擎
存储引擎:指数据被各种不同的技术存储在内存(或文件)中。通过 show engines; 查看可知 —— 仅 InnoDB 存储引擎支持事务
show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| ndbcluster | NO | Clustered, fault-tolerant tables | NULL | NULL | NULL |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| ndbinfo | NO | MySQL Cluster system information storage engine | NULL | NULL | NULL |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+事务的特性(ACID)
- A :原子性(atomicity,或称不可分割性)。事务中的所有操作必须作为一个不可分割的整体执行,要么全部成功提交(
COMMIT),要么全部失败回滚(ROLLBACK),不存在部分执行的中间状态。其实现依赖于数据库的日志机制(如 Undo Log)和事务控制命令。 - C :一致性(consistency)。确保事务执行前后,数据库始终满足预定义的数据完整性约束和业务规则,即使事务执行过程中可能存在临时不一致状态。
- I :隔离性(isolation,又称独立性)。指一个事务的执行不会被其他事务干扰。在生产环境下,多个事务并发执行时,需通过具体的隔离级别控制其相互干扰程度,确保数据一致性。
- D :持久性(durability),指事务提交后,对数据库的数据修改是永久性的,即使发生系统崩溃、断电等故障也不会丢失。其实现依赖于预写日志(WAL)机制和事务日志(如 Redo Log)。
以 A 用户向 B 用户银行转账为例,假设 A 的银行卡余额为 1000 元,B 的银行卡余额为 1000 元,现在需要完成 A 向 B 转账 500 元的这件事。
- A:只存在两种状态
- 转账成功 —— A 的银行卡余额减少 500 元, B 的银行卡余额增加 500 元
- 转账失败 —— 双方的银行卡余额未发生变化
- C:转账前后,双方银行卡的总金额 2000 元是不变的
- I:转账过程中其他事务无法看到中间状态(如 A 已扣款但 B 未到账),且无法修改相关账户数据。需要通过数据库锁机制和隔离级别实现,确保并发操作时数据一致性。
- D:转账成功后,双方银行卡的余额永久被修改,即生成了具体的银行流水条目(银行流水条目是不可篡改的审计记录)。
事务分类
划分为:
-
隐式事务 - 没有明显的开启或结束的标记,事务的自动开启、提交或回滚由 MySQL 内部自动控制,例如一条 DML 语句( insert 、update、delete)就是一个隐式事务。在 MySQL 内部,通过 autocommit 系统变量进行控制,默认情况下该变量的值为 ON
show variables like '%autocommit%'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | autocommit | ON | +---------------+-------+ -
显式事务 - 有明显的开启或结束的标记,若要开启显式事务,则需先关闭隐式事务,也就是
set autocommit=0;, 这仅当前连接中临时生效,一旦退出连接会话并重新连接然,则系统变量的值还是 ON
事务基础使用与特性控制
创建显式事务
基本语法为:
# 开启显式事务
set autocommit=0;
# 开启标记
start transaction;
# 编写事务使用到的SQL语句,insert、update、delete、select
语句1;
语句2;
...
# 结束事务。要么 commit 全部提交,要么 rollback 回滚,二选一
commit;以之前的银行转账为例来说明:
use home;
create table if not exists bank(
id int primary key auto_increment,
bankuser char(15),
balance decimal(10,3)
);
# 插入数据
insert into bank values(null,'A',1000),(null,'B',1000);
# 查询数据
select * from bank;
+----+----------+----------+
| id | bankuser | balance |
+----+----------+----------+
| 1 | A | 1000.000 |
| 2 | B | 1000.000 |
+----+----------+----------+
# 显式事务 commit 示例
set autocommit=0;
start transaction;
update bank set balance=500 where id=1;
update bank set balance=1500 where id=2;
commit;
# 查询数据
select * from bank;
+----+----------+----------+
| id | bankuser | balance |
+----+----------+----------+
| 1 | A | 500.000 |
| 2 | B | 1500.000 |
+----+----------+----------+
# 显式事务 rollback 示例
set autocommit=0;
start transaction;
update bank set balance=1000 where id=1;
update bank set balance=1000 where id=2;
rollback;
# 因为是用回滚结束事务,相当于是两条 SQL 语句做的数据修改只临时存放在内存中,并没有将真正的数据修改写入到文件中永久生效,所以查询时,还是原先的记录。
select * from bank;
+----+----------+----------+
| id | bankuser | balance |
+----+----------+----------+
| 1 | A | 500.000 |
| 2 | B | 1500.000 |
+----+----------+----------+
2 rows in set (0.00 sec)delete 与 truncate
在原先 DML 的内容中就提到过,同样都是清空行数据,两者的区别在于:
- 效率不同 -
delete语法清空数据是以行为单位进行数据的删除,在效率上不如truncate - 风险不同 -
delete语法清空数据后可通过 回滚 的方式恢复数据(回滚通过 binlog);但truncate则是彻底的清空数据,且在相应的日志中没有记录 - 当有自增长的列时,使用
delete删除后再使用insert into,自增长列的值从断点处开始记;而使用truncate清空表的行数据后,插入自增长列的值从 1 开始记 delete有返回值,提升有多少行受影响,但是truncate没有返回值
来看这样的 delete 例子:
# 假设我需要利用事务清空 bank 表的数据
use home;
set autocommit=0;
start transaction;
delete from bank;
rollback;
# 由于 rollback 回滚外加 delete 的特性,因此数据没有发生变化
select * from bank;
+----+----------+----------+
| id | bankuser | balance |
+----+----------+----------+
| 1 | A | 500.000 |
| 2 | B | 1500.000 |
+----+----------+----------+但如果使用 truncate,结果则不一样:
use home;
set autocommit=0;
start transaction;
truncate table bank;
rollback;
# 数据已经清空,无法通过 rollback 恢复数据
select * from bank;
# 当我们再次插入数据时,由于 id 是自增列,因此从初始的 1 开始。
insert into bank values(null, 'A', 2000),(null, 'B', 2000);
select * from bank;
+----+----------+----------+
| id | bankuser | balance |
+----+----------+----------+
| 1 | A | 2000.000 |
| 2 | B | 2000.000 |
+----+----------+----------+查看事务
- 查看当前所有的事务 -
select * from information_schema.innodb_trx; -
查看锁的事务 -
- 8.0.13 版本之前 -
select * from information_schema.innodb_locks; - 8.0.13 版本以及 8.0.13 版本之后 -
select * from performance_schema.data_locks;
- 8.0.13 版本之前 -
回滚点
当事务必须回滚时,可指定回滚点,关键字为 savepoint,必须配合 rollback 一起使用。
比如:
use home;
set autocommit=0;
start transaction;
delete from bank where bankuser='A';
savepoint A;
delete from bank where bankuser='B';
rollback to A;事务并发产生的问题
在实际的生产环境下,会遇到多个事务同时执行的情况,前面的 ACID 特性提到了隔离性,若对事务不隔离,会出现各种并发问题(脏读、不可重复读、幻读)。
脏读(dirty reads)
脏读 - 指读取到了实际并不存在的数据,其产生原因如下图所示:
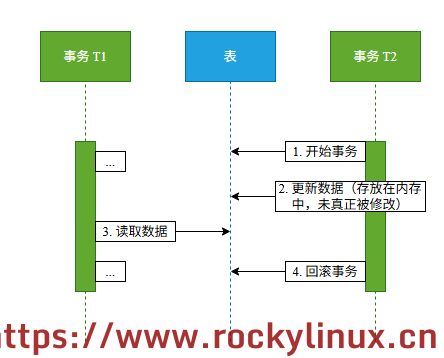
事务 T1 读到了事务 T2 更新但还没有提交的数据,若事务 T2 回滚,则刚刚 T1 读取的数据就是临时且无效的。
不可重复读(Nonrepeatable read)
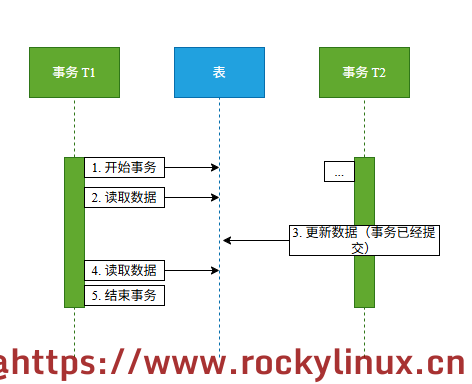
不可重复读 - 指在一个事务内,最开始读到的数据和事务结束之前读到的数据不一致,其产生原因如下:
幻读(Phantom Read)
幻读 - 指在一个事务中,两次或多次读到的行数据结果集不一致
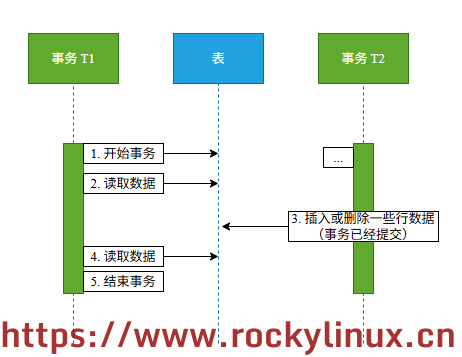
Q:幻读和不可重复读是一样的吗?
不是。不可重复读针对的是已经存在的某一行或多行数据中的字段值(用的是「更新」,关键字 update);幻读针对的是行数据(插入或者删除,关键字为 insert、delete)
隔离级别
事务隔离靠的是隔离级别,不同的隔离级别对应不同的干扰程度,隔离级别越高,数据完整性与一致性越好,但并发性越弱。
| 隔离级别(从低到高) | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 1(READ UNCOMMITTED,读取未提交的数据) | 会出现 | 会出现 | 会出现 |
| 2(READ COMMITTED,读取提交的数据) | 不会出现 | 会出现 | 会出现 |
| 3(REPEATABLE-READ,可重复读,全局默认隔离级别) | 不会出现 | 不会出现 | 会出现 |
| 4(SERIALIZABLE,序列化) | 不会出现 | 不会出现 | 不会出现 |
可通过查询这个系统变量的值来了解当前连接会话的隔离级别:
select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| REPEATABLE-READ |
+-------------------------+read uncommitted 隔离级别的演示
将当前连接会话的隔离级别变更为 read uncommitted 的语句如下:
set session transaction isolation level read uncommitted;创建表并插入数据:
use home;
create table if not exists stuinfo(
id int primary key auto_increment,
stuname varchar(10)
);
insert into stuinfo values(null,'张'),(null,'李');-
出现脏读:
步骤 连接会话 1 连接会话 2 1 set session transaction isolation level read uncommitted;use home;set autocommit=0;start transaction;update stuinfo set stuname='王' where id=2;
请注意此时并没有结束事务2 set session transaction isolation level read uncommitted;use home;set autocommit=0;start transaction;select * from stuinfo;3 rollback;4 rollback;在步骤 2 中,
select * from stuinfo;的输出信息如下:+----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 王 | ←←← 读取到了未提交的虚假数据 +----+---------+
read committed 隔离级别的演示
-
未出现脏读:
步骤 连接会话 3 连接会话 4 1 set session transaction isolation level read committed;use home;set autocommit=0;start transaction;update stuinfo set stuname='王' where id=2;
请注意此时并没有结束事务2 set session transaction isolation level read committed;use home;set autocommit=0;start transaction;select * from stuinfo;3 rollback;4 rollback;在步骤 2 中,
select * from stuinfo;的输出如下:+----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 李 | ←←← 读取到的是连接会话 3 中事务开始之前的真实数据 +----+---------+ -
出现了不可重复读:
步骤 连接会话 5 连接会话 6 1 set session transaction isolation level read committed;use home;set autocommit=0;start transaction;select * from stuinfo;
请注意事务还没有结束2 set session transaction isolation level read committed;use home;set autocommit=0;start transaction;update stuinfo set stuname="赵" where id=2;commit;
事务已经结束3 select * from stuinfo;4 rollback;在步骤 1 中,
select * from stuinfo;的输出如下:+----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 李 | +----+---------+在步骤 3 中,
select * from stuinfo;的输出如下:+----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 赵 | +----+---------+
REPEATABLE-READ 隔离级别的演示
先将数据还原到初始数据状态:
update stuinfo set stuname='李' where id=2;
select * from stuinfo;
+----+---------+
| id | stuname |
+----+---------+
| 1 | 张 |
| 2 | 李 |
+----+---------+-
未出现不可重复读:
步骤 连接会话 7 连接会话 8 1 use home;set autocommit=0;start transaction;select * from stuinfo;
请注意事务还没有结束2 use home;set autocommit=0;start transaction;update stuinfo set stuname='赵' where id=2;commit;3 select * from stuinfo;4 rollback;步骤 1 中,
select * from stuinfo;的输出为:+----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 李 | +----+---------+步骤 3 中,
select * from stuinfo;的输出为:+----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 李 | +----+---------+ -
出现了幻读
依然还原为初始数据:
update stuinfo set stuname='李' where id=2; select * from stuinfo; +----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 李 | +----+---------+步骤 连接会话 9 连接会话 10 1 use home;set autocommit=0;start transaction;select * from stuinfo;
请注意事务未结束2 use home;set autocommit=0;start transaction;insert into stuinfo values(null,'郑');commit;3 select * from stuinfo;4 delete from stuinfo where stuname='郑';5 rollback;步骤 1 中,
select * from stuinfo;的输出记录为两条行数据:+----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 李 | +----+---------+ 2 rows in set (0.00 sec)步骤 3 中,
select * from stuinfo;的输出记录依然为两条行数据:+----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 李 | +----+---------+ 2 rows in set (0.00 sec)但在步骤 4 中,它会提示执行成功,很明显这里出现了幻读:
Query OK, 1 row affected (0.00 sec)
SERIALIZABLE 隔离级别的演示
当开启最高级别的隔离后,它表示在一个事务执行期间(未结束的时候),为了保证读取到表中行数据,会对表中的行数据加一把锁,禁止其他事务对该表执行 insert、update 和 delete 操作。该隔离级别能非常完整的保持数据的一致性与完整性,脏读、不可重复读、幻读这些问题都可以避免,但是它并发性能非常低,所以通常情况下,默认隔离级别其实就足够了,除非有特殊的业务场景。
-
未出现幻读
还原为初始数据:
delete from stuinfo where id=3; select * from stuinfo; +----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 李 | +----+---------+ 2 rows in set (0.00 sec)步骤 连接会话 11 连接会话 12 1 set session transaction isolation level SERIALIZABLE;use home;set autocommit=0;start transaction;select * from stuinfo;
请注意事务未结束2 set session transaction isolation level SERIALIZABLE;use home;set autocommit=0;start transaction;insert into stuinfo values(null,'王');4 commit;5 insert into stuinfo values(null,'王');commit;步骤 1 中,
select * from stuinfo;的输出为两条记录:+----+---------+ | id | stuname | +----+---------+ | 1 | 张 | | 2 | 李 | +----+---------+ 2 rows in set (0.00 sec)在步骤 2 中,
insert into stuinfo values(null,'王');语句会出现一直等待的情况,直到出现:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction我们需要将连接会话 11 的事务结束掉(
commit;),insert into stuinfo values(null,'王');语句则会执行成功,接着commit;提交即可。
Q&A
Q:为什么 MySQL 要全局默认使用 REPEATABLE-READ 隔离级别?
- 一方面是因为该隔离级别既能保证足够的并发性能,同时也兼具解决一些并发问题;
- 另外一方面是历史遗留问题,在 MySQL 5.0 之前的版本中,主从复制仅支持 binlog 的 STATEMENT 这种格式,当采用这种格式并在 Read Committed 隔离级别进行主从复制时会有 bug
Q:能永久更改连接会话的默认隔离级别吗?
可以,需要在配置文件 /etc/my.cnf 中写入:
...
[mysqld]
# READ-UNCOMMITTED 还可以替换为 READ-COMMITTED、REPEATABLE-READ、SERIALIZABLE
transaction-isolation=READ-UNCOMMITTED
...









